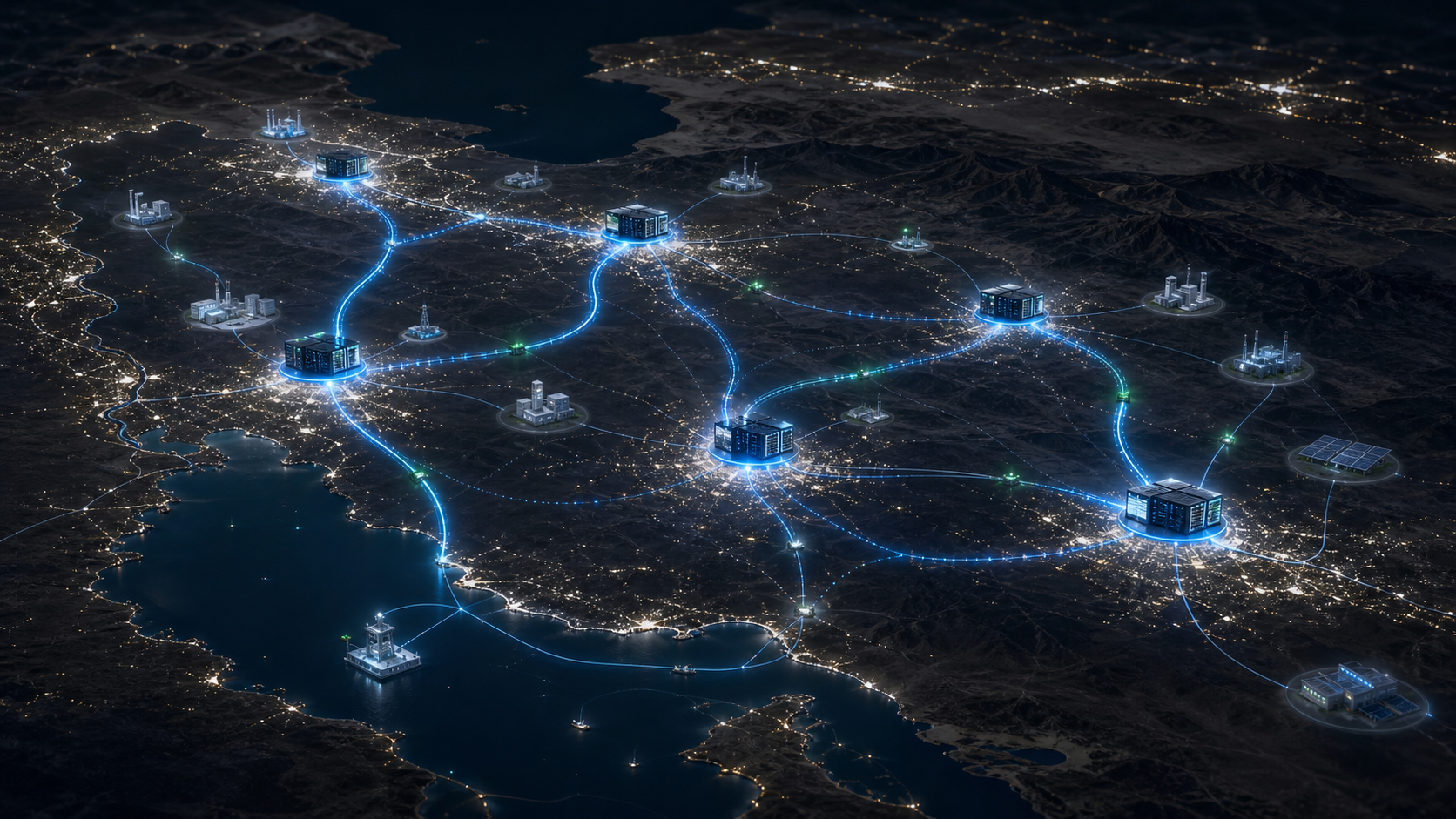
شبکهی دیتاسنترهای هوش مصنوعی در شهرهای بزرگ ایران
زیرساخت محلی برای آموزش، استنتاج، ذخیرهسازی داده، مدلهای فارسی و سرویسهای هوش مصنوعی حساس در نزدیکی کاربران و سازمانها.
تز مرکزی
هوش مصنوعی بدون توان محاسباتی و انرژی محلی، به مصرفکنندهی رابط برنامهنویسی خارجی تبدیل میشود؛ دیتاسنتر هوش مصنوعی بخشی از حاکمیت دیجیتال است.
آنچه عمومی میماند
مزیتهای دادهمحلی، تاخیر، امنیت، اشتغال، توسعه منطقهای و استقلال سرویس.
- چرایی محلیبودن توان محاسباتی، تاخیر، امنیت داده، توسعه منطقهای، اشتغال تخصصی و نقش دیتاسنتر در مدل فارسی.
- معماری سطح بالا شامل خوشه GPU، ذخیرهسازی شیء، ارائه مدل، ابر خصوصی، پیوند لبه شبکه، خنکسازی و عملیات.
- نقشه عمومی شهرها و کاربردها بدون ظرفیت دقیق، مکان دقیق، قرارداد برق یا مشتری لنگر.
آنچه در اتاق سرمایهگذار/داخلی میماند
ظرفیت GPU، انرژی، هزینه سرمایهای/عملیاتی، مکانیابی، قرارداد برق، مدل درآمد و فهرست مشتریان مشتری لنگر.
- مکان دقیق، ظرفیت GPU، تامینکننده، هزینه برق، ظرفیت پست، قرارداد زمین/برق/فیبر، هزینه سرمایهای/عملیاتی و زمانبندی خرید.
- نام مشتریان مشتری لنگر، پیشقراردادها، ظرفیت رزروشده، قیمتگذاری، مدل مالی، ریسک تحریم و جزئیات امنیت فیزیکی/شبکه.
- طراحی دقیق افزونگی، توپولوژی، مسیر اتصال، کلیدهای دسترسی، برنامه رخداد پاسخ و ریسکهای مقرراتی.
معماری و نقشه اجرا
این بخش برای تبدیل هر ایده به مقالهی بلند، یادداشت سرمایهگذار و نقشهی اجرایی استفاده میشود.
معماری
- خوشه GPU
- دریاچه ذخیرهسازی
- ارائه مدل
- ابر خصوصی
- پیوندهای لبه شبکه
- عملیات انرژی
نقشه راه
- مطالعه امکانسنجی شهرها
- پایلوت استنتاج
- گسترش GPU/ذخیرهسازی
- ابر هوش مصنوعی منطقهای
طرح مقالهی بلند
هدف هر سند، مقالهای حداقل ۱۰هزار واژهای با منابع و نسخهی عمومی/خصوصی جداست.
چرا توان محاسباتی زیربناست
انتخاب شهرها
مدل انرژی و خنکسازی
استنتاج در برابر آموزش
داده و امنیت
اقتصاد دیتاسنتر
نقشه توسعه
ریسکها
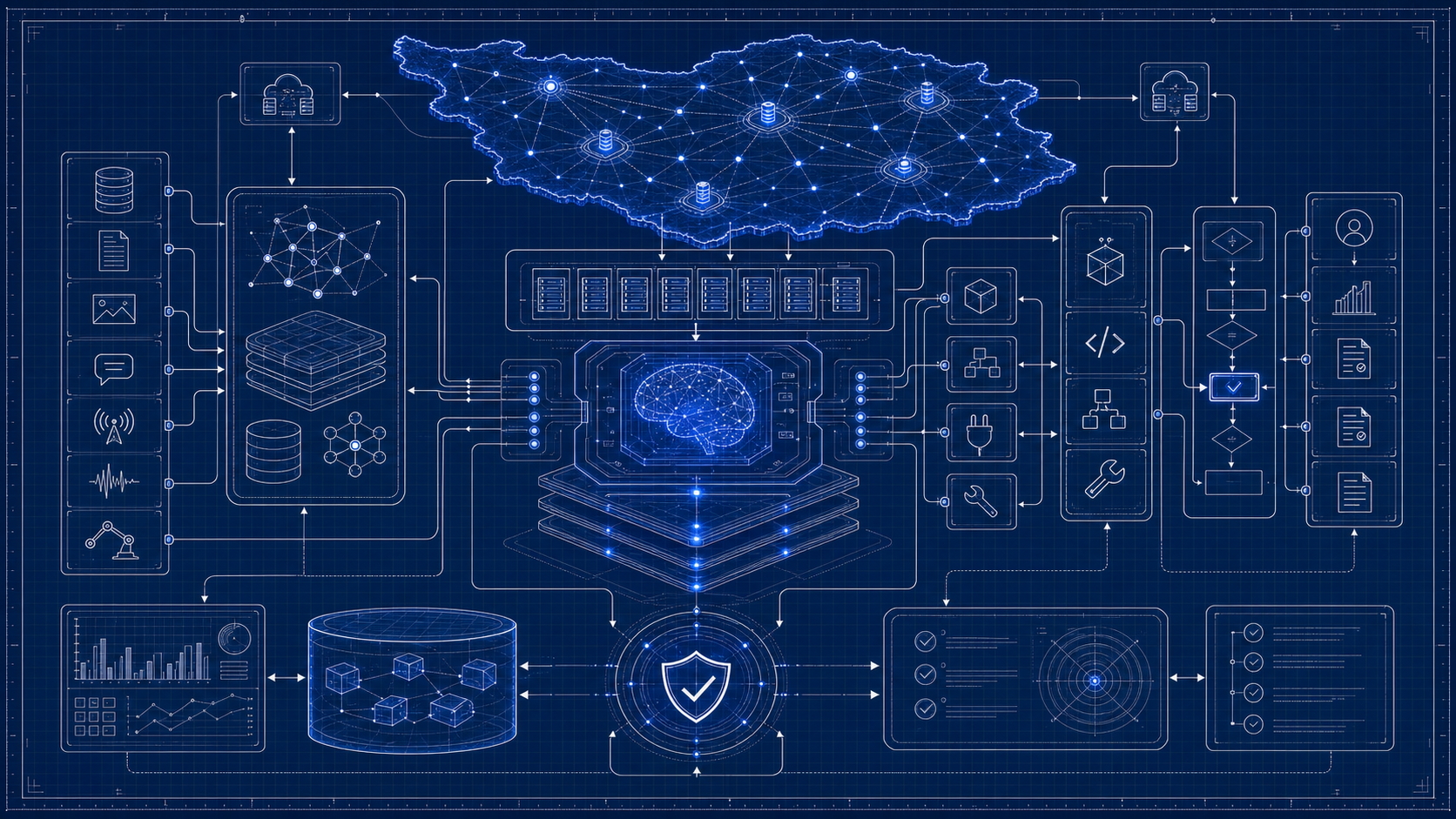
بلوپرینت مقاله
هوش مصنوعی بدون توان محاسباتی و انرژی محلی، به مصرفکنندهی رابط برنامهنویسی خارجی تبدیل میشود؛ دیتاسنتر هوش مصنوعی بخشی از حاکمیت دیجیتال است.
نقشه تصویری فرایند
این تصاویر در میانهی خواندن سند، مسیر اجرا، معماری و نقاط تصمیم را ملموستر میکنند؛ نسخهی کاملتر هر تصویر در گالری پایین صفحه نگهداری میشود.


پیشنویس مقاله
این متن نسخهی نخست مقالهی بلند «شبکهی دیتاسنترهای هوش مصنوعی در شهرهای بزرگ ایران» است. نسخه نهایی باید امکانسنجی، معماری، مدل انرژی، مدل درآمد، نقشه شهرها و ریسکهای سرمایهگذاری را از هم جدا کند.
پردازش زیربنای استقلال هوش مصنوعی است
هوش مصنوعی بدون توان محاسباتی محلی به مصرف رابط برنامهنویسی خارجی محدود میشود. این مصرف در شروع سریع و مفید است، اما وقتی کاربردها به داده حساس، تاخیر پایین، هزینه ثابت، مدل فارسی، استنتاج حجیم و سرویس سازمانی میرسند، زیرساخت محلی اهمیت پیدا میکند. دیتاسنتر هوش مصنوعی فقط محل رک و سرور نیست؛ بخشی از زنجیره ارزش مدل، داده، حافظه، حریم خصوصی و محصول است.
برای ایران، بحث توان محاسباتی باید واقعبینانه باشد. همه چیز از روز اول نیاز به آموزش مدل خوشه عظیم ندارد. بسیاری از کاربردها با استنتاج خوشه، مدلهای متوسط، RAG، ذخیرهسازی و لبه شبکه قابل شروعاند. آموزش مدل بزرگتر یا پیشآموزی ادامهدار میتواند بعد از ساخت داده و تقاضای واقعی بیاید. این نگاه هزینه را کنترل میکند و سرمایهگذار را از یک پروژه زیرساختی بیدرآمد دور نگه میدارد.
انتخاب شهرها: انرژی، فیبر، مشتری لنگر
نقشه دیتاسنتر هوش مصنوعی باید با شهرهای نمادین شروع نشود؛ باید با معیار شروع شود. معیارهای اصلی شامل دسترسی به برق پایدار، امکان خنکسازی، فیبر و شبکه، نزدیکی به مشتریان مشتری لنگر، امنیت فیزیکی، نیروی انسانی، هزینه زمین، ریسک اقلیمی و امکان اتصال به لبه شبکه است. ممکن است بهترین شهر برای پایلوت، لزوماً بزرگترین شهر نباشد؛ ممکن است شهری با انرژی، زمین، دانشگاه و مشتری صنعتی مناسب، بازده بهتری بدهد.
نسخه عمومی میتواند از شبکه شهرها و توسعه منطقهای صحبت کند، اما مکان دقیق و ظرفیت نباید عمومی باشد. مکانیابی دیتاسنتر با ریسک امنیتی، قیمت زمین، قرارداد برق و مذاکره محلی گره خورده است. این جزئیات باید در نسخه خصوصی بماند.
کارت امتیاز شهرها و خط پردازش مشتری لنگر
برای جلوگیری از تصمیم احساسی، انتخاب شهر باید کارت امتیاز داشته باشد. هر شهر باید با معیارهای وزندار سنجیده شود: برق پایدار، قیمت انرژی، ظرفیت توسعه، فیبر، تاخیر به مشتریان هدف، امنیت فیزیکی، دسترسی نیروی متخصص، اقلیم و خنکسازی، هزینه زمین، شریک محلی، ریسک حقوقی/عملیاتی و وجود مشتری لنگر. این کارت امتیاز در نسخه عمومی فقط به شکل روششناسی منتشر میشود؛ اعداد واقعی و شهرهای اولویتدار باید خصوصی بمانند.
مشتری لنگر مهمتر از نام شهر است. اگر یک شهر مشتری سازمانی، کارخانه، دانشگاه، اپراتور یا شریک دیتاسنتری دارد که از روز اول ظرفیت را مصرف میکند، ریسک سرمایه پایینتر میآید. بدون مشتری لنگر، دیتاسنتر به شرطبندی روی تقاضای آینده تبدیل میشود. بنابراین خط پردازش فروش باید همزمان با مکانیابی جلو برود: چه کسی ظرفیت رزروشده میخواهد، چه بارکاریی دارد، چه توافق سطح خدمت میخواهد و چه قرارداد چندماهه یا چندساله حاضر است امضا کند.
نسخه سرمایهگذار باید برای هر شهر یک پرونده داشته باشد: امتیاز، هزینه سرمایهای، هزینه عملیاتی، مشتری لنگر تعهدها، ریسک برق، ریسک فیبر، زمان راهاندازی و مسیر خروج/چرخش. صفحه عمومی فقط باید نشان دهد آپالکسا انتخاب شهر را مهندسی و اقتصادی میبیند، نه تبلیغاتی.
معماری فنی: استنتاج اول، آموزش مدل بعد
پیشنهاد عملی این است که فاز اول دیتاسنتر روی استنتاج، ذخیرهسازی، ارائه مدل، خصوصی ابر و داده پردازش تمرکز کند. این فاز به محصولات آپالکسا کمک میکند: Aira، CognitivX، Socheli، ابزارهای سازمانی، مدل فارسی و داشبوردهای عملیاتی میتوانند از نزدیکترین ظرفیت محاسباتی استفاده کنند. فاز دوم میتواند GPU بیشتری برای تنظیم دقیق، بردار معنایی، پردازش صوت و بینایی ماشین، و در نهایت آموزش مدل اضافه کند.
معماری باید چند سطح داشته باشد: مرکزی خوشه GPU برای بارکاریهای سنگین؛ ذخیرهسازی دریاچه داده برای داده و خروجی قابل تحویل؛ مدل دفتر ثبت برای نسخههای مدل؛ استنتاج دروازه کنترل برای کنترل دسترسی و مصرف؛ مشاهدهپذیری برای هزینه و کیفیت؛ و پیوندهای لبه شبکه برای اتصال مزرعه، کارخانه، فروشگاه یا سازمان. هر سرویس باید چندمحیطی مشتری، ممیزی و سهمیه داشته باشد. بدون این لایهها، دیتاسنتر به زیرساخت خام تبدیل میشود نه محصول قابل فروش.
عملیات چرخه عمر مدل دروازه کنترل و چرخه عمر مدل
دیتاسنتر هوش مصنوعی بدون عملیات چرخه عمر مدل دروازه کنترل به مزرعه GPU تبدیل میشود. هر مدل باید دفتر ثبت، مالک، نسخه، مجموعهداده ردیابی تبار داده، ارزیابی گزارش، مجاز محیطهای مشتری، هزینه پروفایل، تاخیر پروفایل، بازگشت برنامه و خروج از چرخه خطمشی داشته باشد. اگر مدلها بدون این چرخه عمر استقرار شوند، سازمان نمیداند کدام نسخه به کدام پاسخ، خطا یا هزینه وصل بوده است.
دروازه باید استنتاج را کنترل کند: محیط مشتری، مدل مسیر، خطمشی، سهمیه، ثبت رخداد، پوشاندن داده حساس، حافظه موقت، مسیر جایگزین و هزینه انتساب. مدل کوچک، مدل بزرگ، RAG، گفتار، OCR و بینایی ماشین نباید همگی از مسیر مبهم اجرا شوند. هر بارکاری باید بداند داده کجا میرود، خروجی چطور ممیزی میشود و هزینه به کدام مشتری یا محصول اتصال میشود.
این بخش به فروش سازمانی کمک میکند. مشتری فقط GPU نمیخواهد؛ میخواهد مدل خصوصی، گزارش کیفیت، بازگشت و کنترل داده داشته باشد. نسخه عمومی میتواند از چرخه عمر مدل و دروازه کنترل امن حرف بزند. نسخه خصوصی باید دفتر ثبت طرحواره، مسیریابی خطمشی، معیارسنجیها، مدلهای فعال، هزینه هر مسیر و شناختهشده شکست حالتها را نگه دارد.
خرید برق، اتصال به شبکه برق و پرونده مجوزگیری
دیتاسنتر هوش مصنوعی با خرید GPU شروع نمیشود؛ با برق، اتصال شبکه و مجوزهای عملیاتی شروع میشود. هر شهر باید پرونده داشته باشد: ظرفیت برق موجود، مسیر توسعه، امکان قرارداد بلندمدت انرژی، کیفیت فیبر، زمانبندی اتصال متقابل، هزینه پست/ترانس، محدودیت خنکسازی، ریسک خاموشی، مالکیت زمین یا ساختمان، مجوز بهرهبرداری و مسئولیت ایمنی. اگر این موارد قبل از خرید سختافزار روشن نباشند، هزینه سرمایهای به دارایی گیر افتاده تبدیل میشود.
خرید برق باید با مدل بارکاری هماهنگ باشد. استنتاج پایدار ممکن است پروفایل مصرف متفاوتی از آموزش مدل افزایش لحظهای ظرفیت داشته باشد. مشتری لنگر میتواند بخشی از ظرفیت را توجیه کند، اما شبکه برق باید اوج مصرف و خنکسازی را تحمل کند. برنامه باید برای پاسخ به تقاضا، قرارداد انرژی، پشتیبانگیری برق، پنجره نگهداری و محدودیت فصل گرم سناریو داشته باشد. برای ایران، ریسک انرژی و خنکسازی باید در پیشنهاد عمومی بهصورت اصولی گفته شود، اما جزئیات مکانی و قراردادی حساس است.
نسخه عمومی میتواند تاکید کند آپالکسا دیتاسنتر هوش مصنوعی را با ارزیابی انرژی، فیبر، خنکسازی و مشتری لنگر طراحی میکند. نسخه خصوصی باید گزینههای محل استقرار، زیرساخت برق و خدمات شرایط، زمانبندی اتصال برق، هزینه سرمایهای برق، مجوزگیری وضعیت، خطر نقشه، و برنامه مذاکره با مالکان/اپراتورها را نگه دارد. این بخش طرح دیتاسنتر را از ایده سختافزاری به پروژه زیرساختی قابل سرمایهگذاری تبدیل میکند.
انرژی، خنکسازی و اقتصاد عملیاتی
هزینه اصلی دیتاسنتر هوش مصنوعی فقط خرید GPU نیست. برق، خنکسازی، افزونگی، نیروی انسانی، تعمیر، قطعات، شبکه، امنیت، بیمه و تامین مالی همه روی قیمت نهایی تاثیر دارند. مدل اقتصادی باید بین هزینه سرمایهای و هزینه عملیاتی تفکیک کند و از همان اول بهرهبرداری را جدی بگیرد. GPU خالی، سرمایه خوابیده است؛ GPU پر اما بدقیمت، حاشیه سود را از بین میبرد.
مدل درآمد میتواند ترکیبی باشد: رزروشده ظرفیت برای مشتریان مشتری لنگر، مصرف پرداخت به میزان مصرف برای استنتاج، قرارداد استقرار خصوصی، سرویس تنظیم دقیق، ذخیرهسازی و پشتیبانگیری، و بستههای سازمانی برای سازمانهایی که دادهشان نباید از محیط کنترلشده خارج شود. دیتاسنتر باید به بازار محصول وصل باشد، نه اینکه منتظر مشتری نامعلوم بماند.
آب خنکسازی، محیطزیستی محدودیتها و مجوزگیری پایداری
دیتاسنتر هوش مصنوعی فقط برق مصرف نمیکند؛ گرما، آب، صدا، فضا و اثر محیطی هم دارد. در برخی شهرها محدودیت آب یا دمای محیط میتواند طراحی خنکسازی را عوض کند. خنکسازی راهبرد باید بین خنکسازی هوایی، خنکسازی مایع، دفع گرما، مهارت نگهداری، مصرف آب، گردوغبار، و هزینه انرژی تصمیم بگیرد. اگر این موضوع دیر بررسی شود، محل استقرار خوب روی کاغذ در عملیات ناکارآمد یا غیرقابل مجوز میشود.
پایداری مجوزگیری باید بخشی از پرونده شهر باشد. سرمایهگذار و شریک محلی باید ببینند مصرف انرژی، شاخص بهرهوری انرژی هدف، آب مصرف، صدا، پشتیبانگیری برق، گرما استفاده مجدد امکانسنجی، و برنامه مدیریت قطعات/باتری چیست. اینها فقط برای معیارهای زیستمحیطی و حکمرانی ارائه نیستند؛ روی مجوز، هزینه، ریسک قطعی و پذیرش محلی اثر دارند. در ایران نیز محدودیت انرژی و آب میتواند فصلبهفصل حساس شود.
نسخه عمومی میتواند بگوید شبکه دیتاسنتر آپالکسا انرژی، خنکسازی و اثر محیطی را از ابتدا در طراحی میسنجد. نسخه خصوصی باید محل استقرار-اختصاصی خنکسازی طراحی، آب فرضها، محیطزیستی مجوزها، تامینکننده پیشنهاد قیمتها، نگهداری هزینه و خطرهای محلی را نگه دارد. این بخش طرح زیرساخت را واقعگرایانهتر و قابل مذاکرهتر میکند.
GPU خرید سازمانی، قطعات یدکی و چرخه عمر هیات راهبری
تامین GPU برای دیتاسنتر هوش مصنوعی نباید خرید موردی و هیجانی باشد. هر نسل سختافزار باید با بارکاری واقعی سنجیده شود: استنتاج فارسی، بردار معنایی، گفتار، OCR، بینایی ماشین، پردازش خروجی، تنظیم دقیق سبک و پردازش دستهای کارها. ممکن است برای بعضی مسیرها GPU گران بازده ندهد و ترکیب GPU متوسط، پردازش دستهای خوب و زمانبند دقیق بهتر باشد. خرید سازمانی باید به محصول و تقاضا وصل باشد، نه به اعتبارنمایی سختافزار.
چرخه عمر هیات راهبری باید تصمیمهای سختافزاری را کنترل کند: انتخاب تامینکننده، سازگاری راهانداز سختافزار و میانافزار، مصرف برق، ضمانت، قطعات یدکی، زمان تامین، ریسک قطعه تقلبی، برنامه تعمیر، استهلاک، ارزش فروش مجدد و چرخه نوسازی. برای شبکه چندشهری، قطعات یدکی و نیروی تعمیر به اندازه خرید اولیه مهماند. قطعهای که در زمان رخداد پیدا نمیشود، روی توافق سطح خدمت و اعتماد مشتری اثر مستقیم دارد.
صفحه عمومی میتواند بگوید برنامه دیتاسنتر با چرخه عمر مالی و عملیاتی ساخته میشود. نسخه خصوصی باید تامینکننده فهرست کوتاه، قیمت، مسیر واردات یا تامین، قطعات دیرتامین، ضمانت شرایط، هزینه سرمایهای جدولشده، استهلاک زمانبندی و تصمیمهای خرید را در اتاق داده نگه دارد.
نقشه مرجع خوشه و فهرست قطعات مرحلهای
شبکه دیتاسنتر باید با نقشه مرجع تکرارپذیر شروع شود، نه طراحی کاملاً سفارشی برای هر شهر. یک خوشه مرجع میتواند شامل GPU گرهها، CPU/خدمت گرهها، ذخیرهسازی سطح، بالا-سرعت شبکه، ورود ترافیک، پایش، پشتیبانگیری، مدیریت کلید، مدل دروازه کنترل و رک/برق/خنکسازی پروفایل باشد. این نقشه مرجع باید کوچک شروع شود اما مسیر گسترش داشته باشد تا فاز بعدی با معماری تازه از صفر ساخته نشود.
قبض/صورتحساب of مواد/مستندات مرحلهای باید برای چند سناریو نوشته شود: استنتاج کوچک، استنتاج بهعلاوه RAG، گفتار/OCR پردازش دستهای، محتوا پردازش خروجی، تنظیم دقیق سبک و اختصاصی سازمانی محیط مشتری. هر سناریو باید نشان دهد چه قطعاتی لازم است، چه چیزی اختیاری است، چه چیزی دیرتامین است، کدام یدکی باید از ابتدا خریداری شود و چه ظرفیتی قابل فروش است. این کار خرید سازمانی را به محصول و درآمد وصل میکند.
نسخه عمومی میتواند از طراحی مرحلهای و قابل گسترش حرف بزند. نسخه خصوصی باید فهرست قطعات، تامینکننده شناسههای کالا/خدمت، قیمت، جایگزینها، رک چیدمان، برق/خنکسازی پروفایل، سرنخ زمان، یدکی خطمشی و مسیر گسترش را نگه دارد.
اتصال به ANI و مدل فارسی
دیتاسنتر هوش مصنوعی اگر از برنامه مدل فارسی جدا باشد، ارزش راهبردیاش کم میشود. ANI به توان محاسباتی، ذخیرهسازی، بازیابی و ارائه مدل نیاز دارد. برنامه مدل فارسی به خط پردازش داده و تنظیم دقیق نیاز دارد. سختافزار هوشمند و لبه شبکه به ظرفیت نزدیک نیاز دارند. اینها باید یک اکوسیستم دیده شوند: دیتاسنتر، مدل، داده، حافظه و کاربرد.
آپالکسا میتواند در این معماری نقش محصول لایه را داشته باشد. دیتاسنتر بدون نرمافزار فروش سختی دارد؛ نرمافزار بدون توان محاسباتی به رابط برنامهنویسی خارجی وابسته میشود. ترکیب این دو است که پیشنهاد سرمایهگذاری را جدی میکند.
بستهبندی محصولی: GPU خام نفروشیم
فروش GPU خام معمولاً به رقابت قیمتی ختم میشود. اگر دیتاسنتر فقط ظرفیت بفروشد، مشتری آن را با هر ارائهدهنده ارزانتر مقایسه میکند. ارزش بالاتر وقتی ساخته میشود که توان محاسباتی به محصول وصل شود: فارسی ارائه مدل، خصوصی RAG، گفتار/OCR کارها، رسانه پردازش خروجی، امن استنتاج، ارزیابی، ذخیرهسازی و نمای مدیریتی مصرف. این بستهبندی باعث میشود دیتاسنتر فقط زیرساخت نباشد؛ بخشی از هوش مصنوعی ابر آپالکسا شود.
برای مشتری سازمانی، بستهها باید قابل فهم باشند. مثلاً بسته پشتیبانی مشتری فارسی، بسته تحلیل سند، بسته مدل خصوصی سبک، بسته تولید محتوای Socheli، بسته حافظه سازمانی CognitivX و بسته لبه شبکه/بینایی ماشین برای مزرعه یا انبار. هر بسته باید توافق سطح خدمت، سقف مصرف، ذخیرهسازی، حریم خصوصی، ممیزی و قیمت پایه داشته باشد. این زبان فروش، فاصله میان تکنولوژی دیتاسنتر و نیاز مشتری را کم میکند.
نسخه عمومی میتواند این محصولسازی را توضیح دهد. نسخه خصوصی باید قیمت هر بسته، هزینه per کار، بهرهبرداری هدف، حاشیه سود، ظرفیت GPU، ارائهدهنده مسیر جایگزین و مشتری جذب را با عدد مدل کند.
فهرست بارکاری و قیمتگذاری محصولمحور
برای اینکه دیتاسنتر هوش مصنوعی فروختنی شود، باید فهرست بارکاری داشته باشد. مشتری نباید مجبور شود نوع GPU، پردازش دستهای اندازه و هماهنگسازی را بفهمد تا از سرویس استفاده کند. کاتالوگ باید بستههای قابل خرید تعریف کند: فارسی گفتوگو استنتاج، خصوصی RAG، بردار معنایی پردازش دستهای، OCR/گفتار، محتوا پردازش خروجی، مدل ارزیابی، تنظیم دقیق سبک، مصنوعی داده پردازش، و امن دفترچه/نوتبوک برای تیم داده. هر بارکاری باید ورودی، خروجی، توافق سطح خدمت، محلیماندن داده، محدودیت، قیمت و نیاز پشتیبانی داشته باشد.
قیمتگذاری باید محصولمحور باشد، نه فقط by سختافزار. یک کار OCR ممکن است از GPU کمی استفاده کند اما ذخیرهسازی و کنترل کیفیت بیشتری بخواهد. یک پردازش خروجی کار ممکن است زمان طولانی و صف قابل تحمل داشته باشد. یک گفتوگو نقطه پایانی به تاخیر و دسترسپذیری حساس است. یک خصوصی RAG به ورود داده و امنیت کنترلها نیاز دارد. اگر همه اینها فقط با ساعت GPU قیمتگذاری شوند، بعضی سرویسها زیانده و بعضی برای مشتری مبهم میشوند.
نسخه عمومی میتواند نشان دهد آپالکسا ظرفیت هوش مصنوعی را به بستههای محصولی قابل فهم تبدیل میکند. نسخه خصوصی باید فهرست بارکاری دقیق، هزینه مدل، بهرهبرداری فرضها، صف خطمشی، هدف حاشیه سود، ظرفیت رزرو ظرفیت، و قیمت هر بسته را نگه دارد. این بخش برای سرمایهگذار مهم است چون دیتاسنتر را به درآمد قابل مدل تبدیل میکند.
زمانبند ظرفیت و بازار داخلی بارکاریها
اقتصاد دیتاسنتر با بهرهبرداری زنده میماند. باید زمانبند داشته باشیم که بارکاریها را بر اساس اولویت، توافق سطح خدمت، هزینه، نوع GPU، محلیماندن داده، مهلت و محیط مشتری خطمشی مدیریت کند. گفتوگو و استنتاج تعاملی باید مسیر کم-تاخیر داشته باشند؛ بردار معنایی و OCR میتوانند پردازش دستهای شوند؛ پردازش خروجی Socheli میتواند یکشبه یا کم-اولویت اجرا شود؛ تنظیم دقیق باید نقطه ذخیره/بازبینی و سهمیه جدا داشته باشد.
در داخل آپالکسا، یک بازار بارکاری لازم است. Aira، CognitivX، Socheli، هوش مصنوعی ابر، ANI و پروژههای سازمانی همه مصرفکننده ظرفیت هستند. اگر مصرف داخلی بدون برگشت پرداخت باشد، کسی هزینه واقعی را نمیبیند. هر بارکاری باید مرکز هزینه، اولویت، سقف مصرف و مالک داشته باشد. این نظم کمک میکند ظرفیت گران به کار کمارزش اختصاص پیدا نکند.
نسخه عمومی میتواند از مدیریت ظرفیت و توافق سطح خدمت هوشمند حرف بزند. نسخه خصوصی باید زمانبند خطمشی، بیشتعهدی ظرفیت، قیمت داخلی، اولویت صف، جابهجایی در خرابی، رزروشده ظرفیت و داده محلیماندن قوانین را نگه دارد. این بخش به سرمایهگذار نشان میدهد دیتاسنتر فقط خرید سختافزار نیست؛ کنترل لایه کنترل اقتصادی دارد.
ظرفیت رزرو ظرفیت هیات راهبری و فروش-to-عملیات دروازه تصمیم
فروش ظرفیت دیتاسنتر نباید از عملیات جدا باشد. هر قرارداد رزروشده ظرفیت باید از فروش-to-عملیات دروازه تصمیم عبور کند: چه بارکاریی است، چه تاخیر و توافق سطح خدمت میخواهد، چه نوع GPU لازم دارد، چه محلیماندن داده دارد، چه افزایش لحظهای ظرفیت مجاز است، چه پنجره نگهداری دارد و آیا ظرفیت واقعاً موجود یا قابل تامین است. اگر فروش بدون این دروازه تصمیم جلو برود، تیم عملیات با تعهدی روبهرو میشود که شاید انجامپذیر یا سودآور نیست.
ظرفیت رزرو ظرفیت هیات راهبری میتواند سبک باشد اما باید تصمیم را ثبت کند. نماینده فروش، عملیات، مالی، امنیت و محصول باید برای قراردادهای بزرگ یا حساس بررسی کنند که قیمت، حاشیه سود، ریسک بیشتعهدی ظرفیت، نیاز به قطعه، تعهد انرژی/شبکه و مسیر جایگزین چیست. این هیات راهبری همچنین باید تصمیم بگیرد چه زمانی ظرفیت داخلی آپالکسا به مشتری بیرونی فروخته شود و چه زمانی برای محصولهای خود شرکت نگه داشته شود.
نسخه عمومی میتواند از رزرو ظرفیت مسئولانه و توافق سطح خدمت قابل اتکا حرف بزند. نسخه خصوصی باید دروازه تصمیم فهرست بررسی، قرارداد بازبینی، مشتری تعهدها، بیشتعهدی ظرفیت محدودیتها، حاشیه سود آستانهها، ظرفیت پیشبینی و تصمیم ثبت رخداد را نگه دارد. این بخش دیتاسنتر را از فروش خام GPU به کسبوکار عملیاتی تبدیل میکند.
ورود محیط مشتری، بارکاری گواهیپذیری و امنیت بازبینی برای خوشه
دیتاسنتر هوش مصنوعی وقتی مشتری واقعی میگیرد، باید ورود مشتری محیط مشتری داشته باشد. مشتری فقط GPU نمیخواهد؛ باید بارکاری خود را تعریف کند، داده حساسیت را اعلام کند، تصویر/محفظه اجرایی را بررسی کند، سهمیه و صورتحساب را ببیند، کلید و دسترسی بگیرد، و قبل از بهرهبرداری واقعی تست کند. بارکاری گواهیپذیری باید مشخص کند آیا کار برای اشتراکی خوشه مناسب است، اختصاصی محیط مشتری میخواهد، یا به دستگاه آماده نصب/استقرار خصوصی نیاز دارد.
امنیت بازبینی برای خوشه باید با محصول هماهنگ باشد. هر بارکاری باید خروجی قابل تحویل، ثبت رخداد، مجموعهداده، مدل وزن، شبکه دسترسی، ذخیرهسازی، دوره نگهداری و خروجیگیری خطمشی داشته باشد. اگر مشتری محفظه اجرایی خودش را میآورد، اسکن و زمان اجرا خطمشی لازم است. اگر مدل مشتری روی داده حساس کار میکند، جداسازی و ممیزی قویتر لازم است. این ورود مشتری جلوی رخدادهای پرهزینه و مصرف کنترلنشده را میگیرد.
نسخه عمومی میتواند از ورود مشتری امن، گواهیپذیری و رزرو ظرفیت شفاف برای مشتریان دیتاسنتر حرف بزند. نسخه خصوصی باید محیط مشتری جریان کار، گواهیپذیری معیارها، محفظه اجرایی خطمشی، پرسشنامه امنیتی، قیمتگذاری سطحها و مشتری خطر موارد را نگه دارد. این بخش دیتاسنتر را به محصول قابل مصرف سازمانی نزدیک میکند.
پورتال مشتری، رزرو ظرفیت و صورتحساب شفاف
برای اینکه دیتاسنتر به محصول فروختنی تبدیل شود، مشتری باید فقط فاکتور ماهانه نگیرد؛ باید درگاه مصرف داشته باشد. پورتال باید سهمیه، مصرف GPU، تعداد کار، تاخیر، ذخیرهسازی، هزینه هر پروژه، خطاها، توافق سطح خدمت، رزروشده ظرفیت و پیشبینی ماه بعد را نشان دهد. بدون این شفافیت، مشتری سازمانی از هزینه هوش مصنوعی میترسد و تیم فروش هم نمیتواند گسترش را توضیح دهد.
رزرو ظرفیت باید قرارداد محصولی داشته باشد: مشتری چه نوع GPU یا سرویس میگیرد، چه زمانهایی اولویت دارد، چه توافق سطح خدمت دارد، آیا ظرفیت استفادهنشده قابل انتقال مانده است، آیا افزایش لحظهای ظرفیت مجاز است، و اگر ظرفیت در رخداد دردسترسنبودن شد چه اعتبار یا جبران دارد. این قرارداد برای مشتری لنگر مشتریان حیاتی است، چون آنها ریسک هزینه سرمایهای فاز اول را کم میکنند.
صورتحساب نیز باید به بارکاری وصل شود، نه فقط گره. مدلهای ممکن شامل رزروشده ماهانه، پرداخت به میزان مصرف، per-توکن، per-کار، ذخیرهسازی، داده انتقال، مدیریتشده مدل و سازمانی پشتیبانی است. نسخه عمومی میتواند شفافیت مصرف و رزرو ظرفیت را توضیح دهد. نسخه خصوصی باید قیمتگذاری، تخفیف، اعتبار خطمشی، ناخالص حاشیه سود، محیط مشتری صورتحساب طرحواره و مشتری تعهدها را نگه دارد.
محیط مشتری جداسازی، سهمیه اجرای خطمشی و محرمانه استنتاج
اگر شبکه دیتاسنتر به مشتری سازمانی، ANI، مدل فارسی و هوش مصنوعی ابر وصل شود، محیط مشتری جداسازی باید از روز اول معماری شود. مشتری نباید فقط GPU اشتراکی بگیرد؛ باید بداند کار، فایل، دستور، بردار معنایی، ثبت رخداد، حافظه موقت، مدل خروجی قابل تحویل و صورتحساب او از دیگران جداست. برای بارکاریهای حساس، محرمانه استنتاج، کلید اختصاصی، خطمشی جدا، دوره نگهداری محدود و ممیزی خروجیگیری لازم میشود. این قابلیتها محصول میسازند، نه فقط هزینه امنیتی.
سهمیه اجرای خطمشی نیز روی سودآوری و اعتماد اثر مستقیم دارد. هر محیط مشتری باید ظرفیت رزرو، سقف افزایش لحظهای ظرفیت، اولویت، صف خطمشی، مدل مسیر جایگزین، بودجه سقف مصرف و اعلان داشته باشد. اگر مشتری ظرفیت رزرو کرده اما بارکاری همسایه منابع را اشغال کند، توافق سطح خدمت از بین میرود. اگر محیط مشتری بدون سقف کار بسازد، کل خوشه از کنترل خارج میشود. بنابراین زمانبند باید قرارداد فروش، وضعیت صورتحساب و خطر خطمشی را بفهمد، نه اینکه فقط GPU بیکار را پر کند.
نسخه عمومی میتواند بگوید شبکه دیتاسنتر آپالکسا برای محیطهای مشتری جدا، ظرفیت قابل رزرو، ممیزی و استنتاج محرمانه طراحی میشود. نسخه خصوصی باید جداسازی طراحی، زمانبند خطمشی، سهمیه قوانین، هزینه انتساب، کلید-مدیریت جزئیات، مشتری سطحبندی و رخداد موارد را نگه دارد. این بخش دیتاسنتر را از هممکانی ساده به حاکمیتی هوش مصنوعی ابر قابل فروش تبدیل میکند.
فازبندی سرمایه: کوچک، قابل فروش، قابل گسترش
ریسک بزرگ دیتاسنتر هوش مصنوعی این است که سرمایه قبل از تقاضا قفل شود. مسیر بهتر، فازبندی سرمایه است. فاز اول میتواند با ظرفیت محدود و بارکاریهای مشخص شروع شود: استنتاج، بردار معنایی، RAG، گفتار و پردازش خروجی. این ظرفیت باید از همان ابتدا به مشتری لنگر یا محصول داخلی وصل باشد. اگر Aira، Socheli، CognitivX و ابزارهای سازمانی مصرف واقعی ایجاد کنند، بهرهبرداری قابل پیشبینیتر میشود.
فاز دوم وقتی معنا دارد که سه شرط برقرار باشد: تقاضای تکرارشونده، قیمتگذاری قابل سود، و تیم عملیات قابل اتکا. در این مرحله میتوان GPU بیشتر، ذخیرهسازی بزرگتر، افزونگی بهتر و قراردادهای رزروشده اضافه کرد. فاز سوم میتواند به آموزش مدل/تنظیم دقیق سنگین و شبکه چندشهری نزدیک شود. این مسیر برای سرمایهگذار قابل دفاعتر از خرید سنگین تجهیزات بدون خط پردازش فروش است.
نسخه خصوصی باید نقطه عطفهای سرمایهگذاری داشته باشد: چه سطح درآمد یا بهرهبرداری اجازه فاز بعدی را میدهد؛ چه مشتری تعهدها لازم است؛ چه قطعاتی دیرتامین هستند؛ و چه سناریویی باعث توقف یا چرخش میشود. عمومیکردن این جزئیات لازم نیست، اما خود وجود این منطق باید در مقاله عمومی حس شود.
عملیات دیتاسنتر: تیم، مانیتورینگ و قابلیت اعتماد
دیتاسنتر هوش مصنوعی فقط با خرید سختافزار راه نمیافتد. تیم عملیات باید شبکهسازی، لینوکس، GPU محرکها، کوبرنتیز یا هماهنگسازی، ذخیرهسازی، امنیت، پشتیبانگیری، پایش، رخداد پاسخ و ظرفیت برنامهریزی را پوشش دهد. اگر این تیم و فرایند ضعیف باشد، حتی سختافزار خوب هم به زمان ازکارافتادگی، هزینه پنهان و نارضایتی مشتری تبدیل میشود.
مانیتورینگ باید مالی و فنی را با هم ببیند. فقط دانستن GPU دما کافی نیست؛ باید بدانیم هر بارکاری چقدر هزینه ساخته، کدام مشتری از سهمیه رد شده، کدام مدل تاخیر بالا دارد، کدام کار شکست خورده، و کدام گره بهرهبرداری پایین دارد. این مشاهدهپذیری برای سودآوری همانقدر مهم است که برای قابلیت اعتماد.
نسخه عمومی میتواند از قابلیت اعتماد، مشاهدهپذیری و توافق سطح خدمت حرف بزند. نسخه خصوصی باید راهنمای عملیات رخداد، نیروی انسانی برنامه، on-تماس، تامینکننده پشتیبانی، قطعات یدکی، پشتیبانگیری، بحران بازیابی و امنیت بازبینی را نگه دارد.
مرکز عملیات شبکه، توافق سطح خدمت و کنترل ظرفیت
اگر دیتاسنتر قرار است به مشتری سازمانی فروخته شود، باید مرکز عملیات شبکه و فرایند توافق سطح خدمت داشته باشد. مشتری فقط نمیپرسد چند GPU دارید؛ میپرسد زمان دسترسپذیری چیست، رخداد چگونه اطلاعرسانی میشود، تاخیر چطور سنجیده میشود، چه کسی on-تماس است، و اگر کار حساس شکست خورد چه تعهدی وجود دارد.
توافق سطح خدمت باید با نوع بارکاری فرق کند. سرویس گفتوگو و استنتاج تاخیر-حساس است. پردازش پردازش دستهای، بردار معنایی یا پردازش خروجی ممکن است صف داشته باشد. تنظیم دقیق و کارهای سنگین باید زمانبندی و نقطه ذخیره/بازبینی داشته باشند. هر سطح باید SLO، اولویت، تلاش دوباره، سهمیه، هشدار و ارجاع مسیر جدا داشته باشد. بدون این تفکیک، تیم عملیات یا وعده بیش از توان میکند یا همه چیز را مثل کار کمریسک میبیند.
کنترل ظرفیت نیز مستقیم به فروش وصل است. اگر رزروشده ظرفیت بیش از حد فروخته شود، توافق سطح خدمت میشکند. اگر ظرفیت بیش از حد نگه داشته شود، هزینه سرمایهای میخوابد. نسخه خصوصی باید ظرفیت مدل، بیشتعهدی ظرفیت خطمشی، قیمت رزروشده، جابهجایی در خرابی برنامه و مرکز عملیات شبکه نیروی انسانی را دقیق نگه دارد.
لبه منطقهای گرهها و بحران بازیابی
شبکه دیتاسنترهای هوش مصنوعی فقط با یک مرکزی محل استقرار معنا ندارد. بعضی بارکاریها به تاخیر نزدیک نیاز دارند، بعضی به محلیماندن داده منطقهای، و بعضی فقط به حافظه موقت، صف یا استنتاج سبک نزدیک مشتری احتیاج دارند. لبه منطقهای گره میتواند سرویسهای سبکتر را نزدیک شهر یا صنعت اجرا کند: مسیریابی، حافظه موقت، RAG محلی، مدلهای کوچک، پردازش اولیه تصویر یا صوت، و اتصال پایدار به مرکزی خوشه.
فاجعه/خرابی بزرگ بازیابی باید از ابتدا طراحی شود، حتی اگر فاز اول کوچک باشد. پشتیبانگیری، تکثیر داده، مدل خروجی قابل تحویل دفتر ثبت، کلید بازیابی، جابهجایی در خرابی، سرد شروع، صف بازپخش و داده بازیابی باید مسیر روشن داشته باشند. برای مشتری سازمانی، سؤال مهم فقط زمان دسترسپذیری نیست؛ این است که اگر شهر، لینک، برق، ذخیرهسازی یا ارائهدهنده دچار مشکل شد، داده و سرویس چگونه برمیگردد.
نسخه عمومی میتواند شبکه شهرها، لبه شبکه و تداوم سرویس را در سطح معماری توضیح دهد. نسخه خصوصی باید توپولوژی، ظرفیت هر محل استقرار، مسیر فیبر، اهداف بازیابی/زمان بازیابی، پشتیبانگیری کلیدها، تمرینهای جابهجایی در خرابی، هزینه افزونگی و محل استقرارهای اولویتدار را محرمانه نگه دارد.
توپولوژی شبکه، اتصال همتا و محلیماندن داده محدودهها
شبکه دیتاسنتر هوش مصنوعی فقط با داشتن چند گره کامل نمیشود. باید توپولوژی مشخص باشد: ناحیه مرکزی، لبه منطقهای، محل پشتیبان، مسیرهای فیبر، اتصال همتا، پیوندهای خصوصی برای مشتریان بزرگ، و خطمشی انتقال داده بین محدودهها. برای بارکاریهای فارسی و سازمانی، محلیماندن داده محدوده اهمیت دارد: بعضی دادهها فقط در محیط مشتری محلی میمانند، بعضی خروجی قابل تحویلها به مرکزی برای پردازش میروند، بعضی فرادادهها قابل تکثیر داده هستند، و بعضی خروجیها میتوانند عمومی یا خروجیگیری شوند.
اتصال همتا و مسیر شبکه روی تاخیر و هزینه اثر مستقیم دارد. اگر استنتاج برای مشتری سازمانی در شهر دور اجرا شود، تاخیر و تجربه بد میشود. اگر داده سنگین تصویر یا صوت بیبرنامه بین شهرها جابهجا شود، هزینه شبکه و ریسک حریم خصوصی بالا میرود. بنابراین زمانبند باید داده محلیماندن را بفهمد و درگاه مشتری باید نشان دهد داده در کدام محدوده پردازش شده است. این شفافیت برای حاکمیتی ابر کنترلها هم لازم است.
نسخه عمومی میتواند از محدودههای داده، تاخیر بهتر و کنترل انتقال داده حرف بزند. نسخه خصوصی باید شبکه نمودار، اتصال همتا شریکها، مسیرهای فیبر، محدوده خطمشی، جابجایی داده قوانین، پهنای باند قیمتگذاری، امنیت کنترلها و ویژه مشتری محل نگهداری داده تعهدها را نگه دارد. این بخش بسیار حساس است و نباید با نقشه دقیق یا ظرفیت واقعی منتشر شود.
تامین انرژی، خنکسازی و قراردادهای محلی
برق و خنکسازی برای دیتاسنتر هوش مصنوعی یک خط توضیحی نیست؛ گاهی عامل اصلی امکانسنجی است. GPU چگالی بالا یعنی گرما، مصرف پیوسته، نیاز به افزونگی و هزینه عملیاتی سنگین. هر شهر باید از نظر دسترسی برق، پایداری، امکان برق پشتیبان برق پشتیبان UPS/تولیدگر، تعرفه، محدودیت فصل گرم، آب یا روش خنکسازی و ریسک توسعه بررسی شود.
قرارداد محلی میتواند مزیت یا ریسک بسازد. اگر آپالکسا بتواند با شریک صنعتی، دانشگاهی یا سازمانی مشتری لنگر ظرفیت بگیرد، فاز اول کمریسکتر میشود. اگر برق یا فیبر با قرارداد ضعیف باشد، بهترین سختافزار هم به سرویس غیرقابل اعتماد تبدیل میشود. بنابراین برنامه شهرها باید با مذاکره واقعی و تعهد مشتری لنگر گره بخورد.
صفحه عمومی میتواند بگوید مکانیابی بر اساس انرژی، فیبر و مشتری لنگر انجام میشود. نسخه خصوصی باید قیمت برق، شاخص بهرهوری انرژی هدف، طراحی خنکسازی، شریک محلی، هزینه افزونگی و ریسک فصلی را نگه دارد.
پوشش ریسک انرژی، پاسخ به تقاضا و گرما استفاده مجدد امکانسنجی
هزینه انرژی برای دیتاسنتر هوش مصنوعی فقط ردیف هزینه نیست؛ میتواند مزیت یا نقطه شکست باشد. برنامه باید انرژی پوشش ریسک و پاسخ به تقاضا را بررسی کند: قرارداد بلندمدت برق، ظرفیت پشتیبان، امکان کاهش بارکاریهای پردازش دستهای در ساعات گران یا پرریسک، اولویتدهی به استنتاج حساس، و زمانبندی پردازش خروجی یا بردار معنایی در پنجرههای کمهزینهتر. زمانبند باید قیمت و ریسک انرژی را بفهمد، نه فقط صف GPU را.
گرما استفاده مجدد و بهینهسازی خنکسازی در بعضی شهرها ممکن است ارزش جانبی بسازد، اما نباید به وعده تبلیغاتی تبدیل شود. باید امکانسنجی واقعی داشته باشد: چه کسی گرما را مصرف میکند، فاصله چقدر است، هزینه لولهکشی یا سیستم حرارتی چیست، فصلهای استفاده چگونه است و آیا از نظر اقتصادی بهتر از خنکسازی معمولی است یا نه. حتی اگر گرما استفاده مجدد عملی نباشد، گزارش انرژی و شاخص بهرهوری انرژی برای سرمایهگذار و مشتری سازمانی مهم است.
نسخه عمومی میتواند از مدیریت انرژی، زمانبندی هوشمند بارکاری و بهرهوری زیرساخت حرف بزند. نسخه خصوصی باید تعرفهها، قرارداد انرژی، پاسخ به تقاضا قوانین، بارکاری کاهش بار خطمشی، شاخص بهرهوری انرژی هدفها، گرما استفاده مجدد امکانسنجی و سناریوی بدبینانه سناریوها را نگه دارد.
زنجیره تامین امن، میانافزار گواهی صحت و خوشه سختسازی امنیتی
شبکه دیتاسنتر هوش مصنوعی فقط از بیرون تهدید نمیشود؛ زنجیره تامین و میانافزار هم خطر دارند. GPU، کارت شبکه، ذخیرهسازی، تغییر مسیر، مدیریت پایه سرور، میانافزار، راهانداز سختافزار و محفظه اجرایی تصویر هرکدام میتوانند آسیبپذیری یا پیکربندی نادرست داشته باشند. زنجیره تامین امن باید خرید سازمانی منبع، فهرست سریال دستگاهها، میانافزار نسخه، امضاشده بهروزرسانی، ردیابی آسیبپذیری و خروج از سرویس خطمشی داشته باشد.
خوشه سختسازی امنیتی باید برای چندگانه-محیط مشتری هوش مصنوعی خاص باشد. مدل خروجی قابل تحویل، دستور ثبت رخداد، مجموعهداده حافظه موقت، محفظه اجرایی زمان اجرا، GPU زمانبندی، اتصال درونی و مدیریت لایه کنترل باید از محیط مشتری نشت محافظت شوند. اگر یک بارکاری بتواند حافظه موقت یا خروجی قابل تحویل محیط مشتری دیگر را ببیند، حاکمیتی هوش مصنوعی ابر از نظر اعتماد شکست میخورد. گواهی صحت و پیکربندی انحراف تدریجی پایش باید در مرکز عملیات شبکه دیده شود، نه فقط در فهرست بررسی نصب.
نسخه عمومی میتواند از سختسازی امنیتی، گواهی صحت و کنترل زنجیره تامین برای ابر مستقل حرف بزند. نسخه خصوصی باید سختافزار منابع، میانافزار خطپایهها، آسیبپذیری فرایند، خوشه پیکربندیها، امنیت یافتهها، رخداد تمرینها و تامینکننده محدودیتها را نگه دارد. این بخش امنیت دیتاسنتر را از قفل در اتاق به سطح ابر واقعی میبرد.
امنیت فیزیکی، شبکه و حاکمیتی ابر کنترلها
دیتاسنتر هوش مصنوعی برای داده حساس فقط با GPU و برق تعریف نمیشود. امنیت فیزیکی، کنترل ورود، دوربین، زنجیره تحویل سختافزار، بخشبندی شبکه، مدیریت راز، رمزنگاری ذخیرهسازی، کنترل ادمین و ثبت رخداد باید از ابتدا بخشی از طراحی باشد. اگر مشتری سازمانی قرار است داده خود را به این زیرساخت بیاورد، باید بتواند کنترلها را بفهمد و ممیزی کند.
حاکمیتی ابر به معنی قطع کامل از جهان نیست؛ یعنی مسیر داده، مدل، کلید، ارائهدهنده و دسترسی روشن است. بعضی بارکاریها میتوانند روی زیرساخت محلی اجرا شوند، بعضی با ارائهدهنده خارجی مسیر جایگزین داشته باشند، بعضی هرگز نباید از محیط مشتری خارج شوند. این سیاستها باید در کنترل لایه کنترل پیاده شوند، نه فقط در قرارداد.
نسخه عمومی میتواند اصل داده محلی، ممیزی و امنیت-by-طراحی را توضیح دهد. نسخه خصوصی باید شبکه نمودار، دسترسی کنترل، کلید نگهداشت کلید/داده، فیزیکی امنیت، بخشبندی، ادمین رویهها و رخداد پاسخ را نگه دارد.
تامین سختافزار، استهلاک و چرخه عمر مالی
GPU و سرورهای هوش مصنوعی داراییهایی هستند که سریع پیر میشوند. برنامه سرمایهگذاری باید استهلاک، تعمیر، قطعه یدکی، گارانتی، تامین جایگزین، ارزش فروش مجدد و چرخه نوسازی داشته باشد. اگر مدل مالی فقط قیمت خرید را ببیند، هزینه واقعی ظرفیت را کم برآورد میکند.
تدارکات نیز ریسک دارد: زمان تامین، محدودیت واردات، سازگاری قطعات، میانافزار، راهانداز سختافزار، مصرف برق، پشتیبانی تامینکننده و ریسک قطعات تقلبی یا غیرقابل تعمیر. هر نسل سختافزار باید با بارکاریهای واقعی سنجیده شود، نه فقط با معیارسنجی تبلیغاتی. شاید برای بعضی سرویسها CPU یا GPU ضعیفتر با پردازش دستهای بهتر اقتصادیتر از GPU گران باشد.
نسخه سرمایهگذار باید هزینه سرمایهای را با عمر مفید، بهرهبرداری، قیمت فروش سرویس و بهروزرسانی برنامه گره بزند. صفحه عمومی لازم نیست وارد جزئیات تامین شود، اما باید نشان دهد آپالکسا دیتاسنتر را مثل عملیات مالی و محصولی میبیند، نه خرید یکباره تجهیزات.
ظرفیت ثانویه بازار، پیشدستی زمانبند قوانین و بیکار-چرخه درآمدزایی
وقتی ظرفیت GPU رزرو میشود، همیشه بهطور کامل مصرف نمیشود. ظرفیت ثانویه بازار میتواند بیکار چرخهها را به بارکاریهای کماولویت، پردازش دستهای استنتاج، داخلی آموزش مدل، معیارسنجی اجرای آزمایشی یا مشتری ظرفیت لحظهای بفروشد. اما این کار باید با پیشدستی زمانبند قوانین و محیط مشتری جداسازی دقیق باشد؛ مشتری رزروشده نباید حس کند ظرفیتش فروخته شده و در زمان نیاز در دسترس نیست.
پیشدستی زمانبند باید قابل پیشبینی باشد: چه کارهایی قابل قطعاند، چقدر اعلان میگیرند، خروجی قابل تحویل کجا ذخیره میشود، بازپرداخت یا اعتبار چگونه محاسبه میشود، و آیا داده حساس وارد ظرفیت لحظهای استخر عرضه میشود یا نه. بیکار-چرخه درآمدزایی میتواند حاشیه سود را بالا ببرد، اما اگر باعث توافق سطح خدمت نقض تعهد یا نشت شود، کل اعتماد شبکه از بین میرود. بنابراین مالی برج کنترل باید درآمد ظرفیت لحظهای را کنار خطر و رخداد هزینه ببیند.
نسخه عمومی میتواند از بهرهبرداری بهتر ظرفیت و گزینههای قیمتگذاری انعطافپذیر حرف بزند. نسخه خصوصی باید ظرفیت لحظهای قیمتگذاری، پیشدستی زمانبند خطمشی، بارکاری صلاحیت، بهرهبرداری پیشبینیها، توافق سطح خدمت خطر و مشتری قرارداد بندها را نگه دارد. این بخش اقتصاد دیتاسنتر را دقیقتر و سرمایهپذیرتر میکند.
مالی برج کنترل: بهرهبرداری، استهلاک و حاشیه سود
دیتاسنتر هوش مصنوعی به برج کنترل مالی نیاز دارد. داشبورد باید بهرهبرداری، درآمد هر بارکاری، هزینه برق، هزینه خنکسازی، استهلاک، قطعات، نیروی عملیات، هزینه شبکه، شکست هزینه و حاشیه سود هر سرویس را کنار هم نشان دهد. اگر فقط مصرف GPU دیده شود، ممکن است بارکاریی پرمصرف به نظر خوب برسد اما به دلیل تاخیر توافق سطح خدمت، ذخیرهسازی یا پشتیبانی زیانده باشد.
کنترل برج/رک باید تصمیمهای سرمایه را هدایت کند: کدام GPU باید بیشتر خریداری شود، کدام بارکاری بهتر است به پردازش دستهای منتقل شود، کدام مشتری قیمتش پایین است، کدام ظرفیت رزروشده سودآور نیست، کدام قطعه به بهروزرسانی نزدیک است و آیا فاز بعدی سرمایهگذاری مجاز است یا نه. این همان نقطهای است که دیتاسنتر از دارایی سنگین به کسبوکار خط قابل مدیریت تبدیل میشود.
نسخه عمومی میتواند از مدیریت مالی و بهرهوری ظرفیت در سطح بالا حرف بزند. نسخه خصوصی باید نمای مدیریتی واقعی، هزینه تخصیص، استهلاک زمانبندی، حاشیه سود per بارکاری، قیمتگذاری تغییرات، خرید محرکها و سناریوهای سناریوی بدبینانه را نگه دارد. این اطلاعات برای سرمایهگذار مهماند اما برای انتشار عمومی بیش از حد حساس هستند.
ریسکها و مرز عمومی/خصوصی
ریسکهای اصلی شامل تامین سختافزار، تحریم، برق، خنکسازی، کمبود نیروی متخصص، ساخت بیش از نیاز، کمبود مشتری، امنیت فیزیکی، امنیت شبکه، و سرعت تغییر GPUهاست. نسخه عمومی باید نشان دهد این ریسکها شناخته شدهاند؛ نسخه خصوصی باید کاهش ریسک واقعی بدهد.
آنچه باید عمومی باشد: منطق زیرساخت، مزیت تاخیر و داده محلی، معماری سطح بالا، پیوند با مدل فارسی و کاربردها. آنچه باید خصوصی بماند: ظرفیت، مکان، قیمت، قرارداد برق، مشتریان، تامینکننده، امنیت طراحی و مدل مالی دقیق.
گالری تصویر تولیدی
برای هر سند، تصاویر تولیدی و دستورهای تصویرسازی کنار هم نگه داشته میشوند تا نسخه عمومی و نسخه سرمایهگذار قابل گسترش باشند.
گرههای محاسباتی شهری
تصویر فرایند: نمای «گرههای محاسباتی شهری» برای توضیح مسیر اجرای «شبکهی دیتاسنترهای هوش مصنوعی در شهرهای بزرگ ایران». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیسالن GPU محلی
تصویر فرایند: نمای «سالن GPU محلی» برای توضیح مسیر اجرای «شبکهی دیتاسنترهای هوش مصنوعی در شهرهای بزرگ ایران». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومینقشه انرژی و توان محاسباتی
تصویر فرایند: نمای «نقشه انرژی و توان محاسباتی» برای توضیح مسیر اجرای «شبکهی دیتاسنترهای هوش مصنوعی در شهرهای بزرگ ایران». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیمحصولات مرتبط و منابع
منابع پایین، نقطه شروع تحقیق عمیقترند؛ برای نسخه نهایی هر مقاله باید منابع بیشتری اضافه شود.