برنامهی مدل بنیادین و دادهی فارسی
یک برنامهی جدی برای جمعآوری، پاکسازی، برچسبگذاری، ارزیابی و آموزش مدلهای فارسی که واقعاً در زبان و فرهنگ فارسی فکر کنند.

تز مرکزی
سختترین بخش مدل فارسی معماری نیست؛ دادهی تمیز، برچسبخورده، متوازن، قابلارزیابی و متعلق به زمینهی فارسی است.
آنچه عمومی میماند
چرا هوش مصنوعی فارسی نباید فقط ترجمهی مدل خارجی باشد و چرا داده/برچسبگذاری مزیت اصلی است.
- چرایی مدل فارسی جدی، تفاوت فارسیگویی و فارسیفهمی، مسئله داده، برچسبگذاری، معیارسنجی و هویت زبانی.
- معماری سطح بالا از پیکره داده تا پاکسازی، استودیوی برچسبگذاری، ارزیابی، ادامه پیشآموزی، همراستاسازی و اتصال به حافظه.
- نقش محصولات آپالکسا بهعنوان سطحهای واقعی ارزیابی و کاربرد، بدون انتشار داده خام یا قراردادهای داده.
آنچه در اتاق سرمایهگذار/داخلی میماند
منابع داده، قراردادهای داده، خط پردازش پاکسازی، هزینه برچسبگذاری، معیارسنجی اختصاصی و مسیر آموزش/تنظیم دقیق.
- فهرست منابع داده، قراردادهای مجوز، داده خام، نمونههای حساس، هزینه پاکسازی/برچسبگذاری و کیفیت هر منبع.
- معیارسنجیهای اختصاصی، دستور/ارزیابیهای داخلی، نقاط ضعف مدل، ظرفیت توان محاسباتی، هزینه آموزش/تنظیم دقیق و زمانبندی دقیق.
- شریکهای دانشگاهی/دادهای، قراردادهای احتمالی، سیاست حذف/ناشناسسازی و ریسک حقوقی داده.
معماری و نقشه اجرا
این بخش برای تبدیل هر ایده به مقالهی بلند، یادداشت سرمایهگذار و نقشهی اجرایی استفاده میشود.
معماری
- جذب پیکره داده
- نرمالسازی
- استودیوی برچسبگذاری
- معیارسنجیهای فارسی
- ادامه پیشآموزی
- همراستاسازی
- اتصال حافظه
نقشه راه
- فهرست داده و مجوزها
- پاکسازی/نرمالسازی فارسی
- بنچمارک و ارزیابی
- مدلهای کوچک/میانی
- مدل بزرگتر با دیتاسنتر محلی
طرح مقالهی بلند
هدف هر سند، مقالهای حداقل ۱۰هزار واژهای با منابع و نسخهی عمومی/خصوصی جداست.
مسئله مدلهای ترجمهمحور
چالش نیمفاصله و نویسهها
دادهی دامنهای
برچسبگذاری انسانی
بنچمارک فارسی
معماری مدل
هویت و ایمنی
اتصال به CognitivX
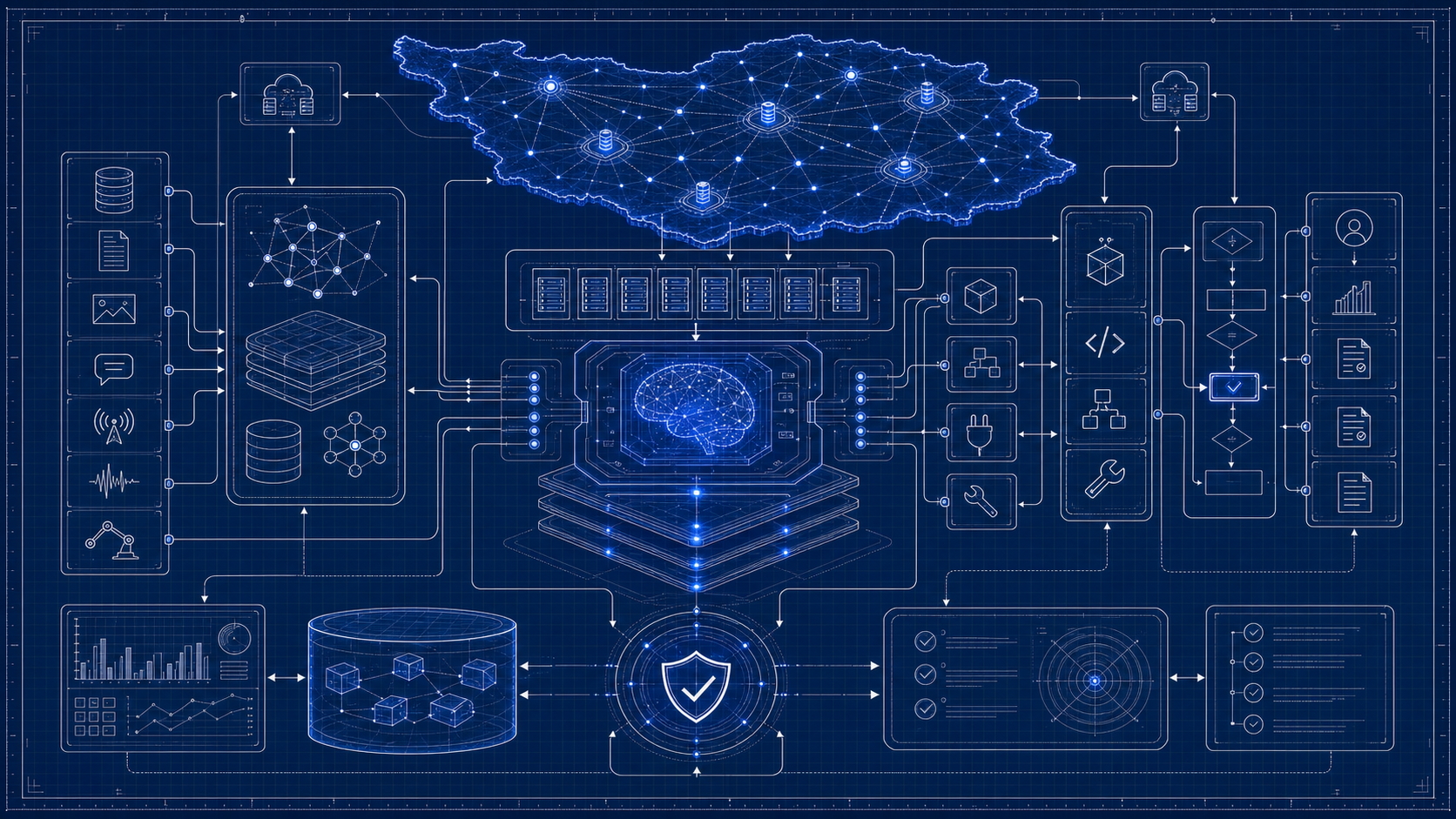
بلوپرینت مقاله
سختترین بخش مدل فارسی معماری نیست؛ دادهی تمیز، برچسبخورده، متوازن، قابلارزیابی و متعلق به زمینهی فارسی است.
نقشه تصویری فرایند
این تصاویر در میانهی خواندن سند، مسیر اجرا، معماری و نقاط تصمیم را ملموستر میکنند؛ نسخهی کاملتر هر تصویر در گالری پایین صفحه نگهداری میشود.


پیشنویس مقاله
این متن نسخهی نخست مقالهی بلند «برنامهی مدل بنیادین و دادهی فارسی» است. هدف نهایی، تبدیل آن به مقاله/گزارش راهبردی بیش از دههزار واژهای با نسخهی عمومی و نسخهی سرمایهگذار است.
مسئله: فارسیگویی با فارسیفهمی یکی نیست
بخش بزرگی از تجربههای امروز «هوش مصنوعی فارسی» در واقع یک رابط فارسی روی مدلهایی است که با جهان زبانی، آموزشی، حقوقی، تجاری و فرهنگی دیگری شکل گرفتهاند. چنین سیستمی میتواند جملهی فارسی تولید کند، اما این به معنای فارسیفهمی عمیق نیست. تفاوت مهمی میان مدلی که فارسی را بهعنوان خروجی تولید میکند و مدلی که داده، ارزیابی، دستور زبان، واژگان، لحن، کاربرد و هویت فارسی در هستهی آموزش و همترازیاش نشسته وجود دارد.
این تفاوت در کارهای ساده ممکن است پنهان بماند. پرسش عمومی، ترجمه، خلاصهسازی سطحی یا گفتوگوی روزمره میتواند ظاهراً خوب پیش برود. اما وقتی وارد فرمهای اداری، اصطلاحات حسابداری، مکاتبهی رسمی، پشتیبانی مشتری، گویش محلی، محتوای آموزشی، روایت ادبی، قرارداد، قانون، کشاورزی، سلامت یا کسبوکار ایرانی میشویم، سطحیبودن فارسی آشکار میشود. مدل ممکن است لحن را اشتباه بگیرد، نیمفاصله و شکل درست واژگان را نادیده بگیرد، اصطلاح محلی را با معادل انگلیسی ذهنی تفسیر کند، یا پاسخی بدهد که ظاهراً روان اما از نظر بافت اجتماعی و کاربردی غلط است.
تز آپالکسا این است که مدل فارسی جدی، فقط با دستور فارسی ساخته نمیشود. چنین مدلی به برنامهی داده نیاز دارد: گردآوری، پاکسازی، نرمالسازی، برچسبگذاری، ارزیابی، همترازی، و سپس اتصال به حافظه و کاربردهای واقعی. معماری مدل مهم است، اما معماری بدون دادهی درست، مثل کارخانهای است که مواد خامش آلوده، تکراری، نامتوازن و بیبرچسب است.
چرا سختترین بخش، داده است
در سالهای اخیر، معماریهای ترنسفورمر، ترکیب متخصصها، بازیابی-تقویتشده تولید، تنظیم دقیق و پیشآموزی ادامهدار به دانش عمومی صنعت تبدیل شدهاند. تیمهای فنی میتوانند مقالهها و پیادهسازیهای متنباز را بخوانند، مدلهای پایه را انتخاب کنند و مسیر فنی را با آزمون و خطا جلو ببرند. اما دادهی فارسی باکیفیت، آماده و قابل اعتماد، چیزی نیست که فقط با دانلود چند پیکره داده حل شود.
دادهی فارسی با مسئلههای خاص خودش میآید: عربی و فارسی بودن حروف ی و ک، نیمفاصله، اعداد فارسی و لاتین، متنهای OCR شده با خطا، اسناد اسکنشده، محتوای محاورهای، فینگلیش، گویشها، ادبیات کلاسیک، مکاتبات اداری، متن حقوقی، اصطلاحات بازاری، گفتوگوی پشتیبانی، دادهی صوتی، و ترکیب همهی اینها با نویز وب. اگر این داده بدون برنامه وارد مدل شود، مدل همان آشفتگی را یاد میگیرد.
پاکسازی داده به معنای حذف چند کاراکتر نیست. باید موارد تکراری حذف شوند، منابع کمکیفیت وزن کمتر بگیرند، دادههای حساس شناسایی شوند، مجوز و مالکیت داده بررسی شود، سبکهای زبانی از هم تفکیک شوند، و تعادل میان زبان رسمی، محاورهای، تخصصی و فرهنگی حفظ شود. برای مدل فارسی، پیکره داده باید هم زبان روزمره را بشناسد و هم زبان سازمان، مالیات، فروشگاه، کشاورزی، سلامت، آموزش و قانون را.
توکنساز، نیمفاصله و استاندارد نرمالسازی فارسی
مدل فارسی جدی باید پیش از آموزش مدل درباره شکل زبان تصمیم بگیرد. نیمفاصله، ی و ک عربی/فارسی، اعداد فارسی و لاتین، نشانهگذاری، واژههای چسبیده، فاصلههای OCR، فینگلیش، نامهای خاص، تاریخ جلالی و ترکیب فارسی/انگلیسی فقط مسئله زیبایی متن نیستند؛ روی توکنسازی، بردار معنایی، بازیابی، ارزیابی و هزینه استنتاج اثر میگذارند. اگر خط پردازش یک بار «می رود» و بار دیگر «میرود» را بیمنطق نگه دارد، مدل و جستوجو سیگنال ضعیف میگیرند.
استراتژی نرمالسازی نباید همه تفاوتها را کورکورانه حذف کند. بعضی تفاوتها خطای تایپیاند و باید اصلاح شوند؛ بعضی تفاوتها سبک، گویش، رسمی/محاورهای یا نشانه دامنه هستند و باید حفظ شوند. برای مثال زبان گفتوگوی پشتیبانی، متن حقوقی، شعر، پیام کودک، رونوشت تماس و فاکتور فروشگاه با یک قانون واحد پاکسازی نمیشوند. برنامه داده باید نسخه خام، نسخه نرمالسازیشده و فراداده تغییر را نگه دارد تا هم مدل زبان طبیعی را ببیند و هم بازیابی و ارزیابی قابل تکرار باشد.
نسخه عمومی میتواند توضیح دهد که آپالکسا فارسی را در سطح نگارش و دستور زبان جدی میگیرد، نه فقط خروجی فارسی تولید میکند. نسخه خصوصی باید توکنساز آزمایشها، نرمالسازی قوانین، خطاهای OCR، هزینه اثر توکنسازی، ابزارهای کیفیت بررسی و تصمیمهای حفظ یا حذف نشانههای زبانی را نگه دارد.
گویش/ثبت نمونهگیری برنامه و پوشش دیردم بلند فارسی
داده فارسی اگر فقط از متن رسمی تهرانمحور یا وب عمومی بیاید، مدل در کاربردهای واقعی کم میآورد. نمونهگیری برنامه باید گویش، ثبت، سن، صنف، شهر، رسانه، صوت/متن، رسمی/محاورهای، پشتیبانی مشتری، داستان، سند اداری و گفتوگوی چندنوبتی را جدا بسنجد. هدف این نیست که همه گویشها را از روز اول کامل پوشش دهیم؛ هدف این است که سوگیری داده را ببینیم و دیردم بلند را آگاهانه اولویتبندی کنیم.
دفتر ثبت فارسی روی محصول اثر مستقیم دارد. پاسخ رسمی بانکی، گفتوگوی خانوادگی، پیام فروش، پاسخ پشتیبانی، روایت کودک و دستور اداری نباید یک لحن داشته باشند. اگر مجموعهداده ثبت را برچسب نکند، مدل ممکن است پاسخ درست اما با لحن اشتباه بدهد. نمونهگیری برنامه باید نشان دهد برای هر محصول آپالکسا چه ثبتهایی لازم است و کدامها فعلاً خارج از دامنه میمانند.
نسخه عمومی میتواند بگوید برنامه داده فارسی آپالکسا به گویش، لحن و کاربردهای واقعی فارسی توجه دارد. نسخه خصوصی باید نمونهگیری سهمیهها، منبع شریکها، تحلیل شکاف، هزینه per بخش مخاطب، خطرهای سوگیری، و برنامه جذب داده دیردم بلند را نگه دارد. این بخش برنامه مدل فارسی را از پیکره داده عمومی به پوشش محصولی دقیقتر تبدیل میکند.
برچسبگذاری فارسی باید فارسیزاد باشد
یکی از خطاهای رایج در ساخت مدلهای محلی، ترجمهی دستور مجموعهدادههای انگلیسی است. ترجمه میتواند نقطه شروع باشد، اما اگر بدنهی اصلی دستورها و ارزیابیها از انگلیسی ترجمه شده باشد، مدل همچنان الگوی مسئلهسازی انگلیسی را یاد میگیرد. کاربر فارسی فقط به زبان فارسی سؤال نمیپرسد؛ مسئله را هم با منطق زندگی، اداره، کسبوکار و فرهنگ فارسی طرح میکند.
برچسبگذاری فارسی باید سناریوهای واقعی را پوشش دهد: کارمند پشتیبانی که باید به مشتری ناراضی جواب دهد؛ فروشندهای که اختلاف موجودی و فاکتور دارد؛ دانشآموزی که توضیح ساده میخواهد؛ مدیر یک آژانس که کمپین چندکاناله دارد؛ کشاورزی که از آب، زمین و محصول میپرسد؛ پزشک یا کلینیکی که باید با احتیاط و ارجاع درست پاسخ دهد؛ کاربر عمومی که با لحن محاورهای و گاهی مبهم سؤال میکند.
این یعنی تیم برچسبگذاری فقط مترجم نیست. باید دستورالعمل سبک، خطمشی ایمنی، سطح رسمی/غیررسمی، معیار صحت، معیار مفیدبودن، و معیار هویت محلی داشته باشد. خروجی خوب فارسی باید علاوه بر درستبودن، طبیعی، محترمانه، دقیق، و متناسب با موقعیت باشد.
بازار کار ارزیاب و داده نیروی کار فارسی
برنامه مدل فارسی به نیروی انسانی متخصص نیاز دارد: ویراستار، زبانشناس، معلم، کارشناس پشتیبانی، کارشناس حقوقی، حسابدار، کارشناس کشاورزی، راوی، اپراتور تماس و بازبین ایمنی. این نیروها فقط برای تولید برچسب نیستند؛ باید خطا را توضیح دهند، مثال بد و خوب بسازند، اختلاف نظر را حل کنند و طلایی بستههای قابل اعتماد بسازند. اگر داده نیروی کار پراکنده و بیکیفیت باشد، مدل در ظاهر فارسی بهتر میشود اما در کاربرد واقعی خطای عمیق میدهد.
آپالکسا میتواند این نیاز را به برنامه عملیاتی و حتی بازار کار داخلی وصل کند. MoltJobs میتواند بخشی از کارهای ارزیابی را به وظیفههای قابل سنجش تبدیل کند: اصلاح نیمفاصله، تشخیص لحن، رتبهبندی پاسخ، ساخت سناریوی پشتیبانی، ارزیابی هذیان مدل، رونوشت اصلاح، یا ساخت معیارسنجی دامنهای. هر وظیفه باید معیار داوری، نمونه، سطح دسترسی داده، توافق محرمانگی و کیفیت بازبینی داشته باشد.
نسخه عمومی میتواند بگوید مدل فارسی جدی با کار انسانی فارسیزبان ساخته میشود. نسخه خصوصی باید نرخ پرداخت، سطح مهارت، ظرفیت ارزیابها، کنترل کیفیت چندمرحلهای، اختلافنظر برچسبگذارها، ابزار برچسبگذاری، و هزینه هر هزار نمونه را در مدل مالی نگه دارد.
ارزیابی: بدون معیارسنجی فارسی، کیفیت قابل ادعا نیست
اگر مدل فارسی با معیارسنجیهای عمومی انگلیسیمحور سنجیده شود، بخش مهمی از کیفیت واقعی پنهان میماند. یک مدل ممکن است در استدلال عمومی یا ترجمه امتیاز مناسبی بگیرد اما در نگارش رسمی فارسی، نیمفاصله، اصطلاحات حقوقی، حسابداری ایران، تاریخ جلالی، یا گفتوگوی پشتیبانی فارسی ضعیف باشد.
برنامهی جدی مدل فارسی باید معیارسنجیهای چندلایه داشته باشد: دستور زبان و نگارش؛ واژگان محلی و تخصصی؛ درک متن رسمی و اداری؛ گفتوگوی محاورهای؛ اعتمادپذیری و هذیان مدل؛ ایمنی و حریم خصوصی؛ کارهای کسبوکار؛ پردازش صوت و رونوشت؛ و سناریوهای فرهنگی/هویتی. هر معیارسنجی باید نسخهی عمومی پژوهشی و نسخهی خصوصی عملیاتی داشته باشد.
آپالکسا میتواند از محصولات خود برای ساخت سناریوهای ارزیابی استفاده کند. Aira سطح مصرفی و گفتوگویی را میدهد. بارکد زبان فروشگاه، حسابداری، کالا، فاکتور و انطباق ایران را میدهد. Aira پشتیبانی و فروش زبان پشتیبانی، فروش و پیگیری را میدهند. Nahid زبان روایت، داستان و صوت را به برنامه وصل میکند. CognitivX هم لایهی حافظه و زمینه را برای ارزیابی تعاملهای بلندمدت فراهم میکند.
آلودگی داده کنترل و جداسازی آموزش/ارزیابی
یکی از خطرهای پنهان برنامه مدل فارسی، آلودگی ارزیابی است. اگر همان داده یا سناریوهایی که برای آموزش مدل، تنظیم دقیق یا دستور تنظیم دقیق استفاده شدهاند وارد معیارسنجی شوند، امتیاز مدل بهتر از واقعیت دیده میشود. این مشکل در فارسی جدیتر است چون مجموعهدادههای باکیفیت کمترند و وسوسه استفاده مجدد زیاد است. برنامه باید از ابتدا آموزش، اعتبارسنجی، ارزیابی، آزمون تهاجمی و نمایش اولیه بسته را جدا نگه دارد.
آلودگی داده کنترل فقط با نامگذاری فایل حل نمیشود. هر مجموعهداده باید شناسنامه داده، هش، منبع، کاربرد مجاز و تقسیم داده خطمشی داشته باشد. اگر متن ناشر فقط برای ارزیابی مجاز است، نباید وارد آموزش مدل شود. اگر مکالمه پشتیبانی ناشناسشده برای معیارسنجی استفاده میشود، نباید دستورهای همان معیارسنجی در تنظیم دقیق بعدی مصرف شوند. اگر داده مصنوعی تولید میشود، باید برچسب مصنوعی و منبع دستور داشته باشد تا مدل روی بازتاب/اکوهای خودش بیشبرازش نکند.
نسخه عمومی میتواند بگوید آپالکسا کیفیت مدل فارسی را با معیارسنجیهای تمیز و قابل دفاع میسنجد. نسخه خصوصی باید آلودگی داده اسکنر، مجموعهداده هشها، تقسیم داده قوانین، ارزیابی فهرستهای داده، آزمون تهاجمی مجموعهها، مصنوعی-داده برچسبها و رخدادهای آلودگی احتمالی را نگه دارد. این بخش برای سرمایهگذار و پژوهشگر مهم است چون کیفیت ادعاشده را قابل اعتماد میکند.
مصنوعی داده خطمشی و افزایش داده فارسی کنترلشده
مصنوعی داده میتواند شکافهای فارسی را پر کند، اما اگر بدون سیاست ساخته شود، خطای مدل را تقویت میکند. برای فارسی، تولید مصنوعی ممکن است در سناریوهای نادر، مکالمات پشتیبانی، فرم اداری، اعتراض مشتری فروش، متن کودک، رونوشت نویزی یا مثالهای ایمنی مفید باشد. اما داده مصنوعی نباید جایگزین مشاهده واقعی زبان شود و نباید با داده انسانی-برچسبخورده مخلوط شود بدون اینکه برچسب و وزن جدا داشته باشد.
هر نمونه مصنوعی باید ردیابی منشا داشته باشد: دستور، مدل تولیدکننده، هدف، دامنه تخصصی، سطح بازبینی انسانی، نسخه معیار داوری و کاربرد مجاز. برای بعضی کاربردها، مصنوعی فقط برای آزمون تهاجمی یا گرم-شروع مفید است؛ برای بعضی، پس از بازبینی انسانی میتواند وارد دستور تنظیم دقیق شود؛ برای معیارسنجی اصلی، مصنوعی باید با احتیاط و جداسازی کامل استفاده شود. همچنین باید مراقب باشیم مصنوعی فارسی بیش از حد رسمی، ترجمهزده یا شبیه سبک یک مدل خاص نشود.
نسخه عمومی میتواند بگوید آپالکسا از داده مصنوعی فقط به شکل کنترلشده و با ارزیابی انسانی استفاده میکند. نسخه خصوصی باید مصنوعی دستورها، دستورالعملهای تولید، کیفیت آستانهها، هزینه بازبینی انسانی، آلودگی داده قوانین، شکست نمونهها و وزندهی داده مصنوعی را نگه دارد.
معماری پیشنهادی: از پیکره داده تا حافظه
مسیر عملی نباید با ادعای ساخت یک مدل عظیم از روز اول شروع شود. مرحلهی اول، برنامهی داده و ارزیابی است: فهرست موجودی منابع، پاکسازی، نرمالسازی، برچسبگذاری، معیارسنجی و خط پردازش تکرارپذیر. مرحلهی دوم، ادامهآموزی یا تنظیم دقیق مدلهای مناسب روی دادهی فارسی باکیفیت است. مرحلهی سوم، مدلهای تخصصی کوچکتر برای کاربردهای مشخص است: پشتیبانی، خردهفروشی، اسناد، صوت، کشاورزی، فروش و محتوا. مرحلهی چهارم، با رشد توان محاسباتی و دیتاسنتر محلی، آموزش/ادامهآموزی مدلهای بزرگتر است.
در این معماری، مدل تنها نیست. مدل زبانی باید با بازیابی، ابزار، حافظه، کنترل دسترسی و ممیزی کار کند. CognitivX در اینجا لایهی حافظه است: زمینهی کاربر و سازمان را نگه میدارد، داده را فقط در لحظه مناسب بازیابی میکند، و اجازه میدهد تجربه از هر نشست به نشست بعدی رشد کند. مدل فارسی بدون حافظه، هر بار از صفر شروع میکند؛ حافظه بدون مدل فارسی، زمینه را دارد اما زبان و استدلال بومی کافی ندارد. ترکیب این دو، زیرساخت اصلی است.
لایهی استقرار نیز مهم است. برای کاربردهای حساس، استنتاج باید در داخل کشور یا در محیط کنترلشده انجام شود. این برنامه به ابتکار دیتاسنتر هوش مصنوعی وصل میشود: دادهی محلی، مدل فارسی، حافظه لایه و سرویسهای سازمانی باید بتوانند روی زیرساختی اجرا شوند که تاخیر، امنیت، هزینه و حاکمیت داده را جدی میگیرد.
نقشه توان محاسباتی و استراتژی اندازه مدل
برنامه مدل فارسی نباید توان محاسباتی را مثل یک خرید سختافزاری جدا ببیند. توان محاسباتی باید از نیاز داده، ارزیابی و محصول تبعیت کند. در فاز اول، ارزش اصلی در مجموعهداده دفتر ثبت، معیارسنجی، تنظیم دقیقهای کوچک، بردار معنایی و استنتاج کنترلشده است. در این فاز، مدلهای کوچک و متوسط که برای دامنههای مشخص بهتر تنظیم شدهاند میتوانند از مدل بزرگ اما بیریشه اقتصادیتر باشند. هدف این نیست که از روز اول بزرگترین مدل ساخته شود؛ هدف این است که هر ریال توان محاسباتی کیفیت فارسی قابل اندازهگیری بسازد.
فاز دوم میتواند پیشآموزی ادامهدار روی پیکره دادههای مجاز و پاکشده را اضافه کند. این فاز باید فقط وقتی شروع شود که برنامه داده بالغ شده، معیارسنجیها آمادهاند و چند محصول آپالکسا به مدل بهتر نیاز واقعی نشان دادهاند. اگر آموزش مدل قبل از داده و ارزیابی شروع شود، هزینه GPU به خروجی نمایشی تبدیل میشود. اگر آموزش مدل بعد از داده آمادگی و محصول تقاضا شروع شود، هر اجرای آزمایشی مدل با تصمیم تجاری و معیار کیفیت همراه است.
استراتژی اندازه مدل باید سبدی باشد: مدل کوچک برای مسیریابی، طبقهبندی و استخراج؛ مدل متوسط برای پشتیبانی، فروش، اسناد و تولید محتوا؛ مدل بزرگتر یا ترکیب ترکیب متخصصها/بازیابی دانش برای استدلال، مکالمه عمیق و کاربردهای ملی. دیتاسنتر محلی در این نقشه نقش شتابدهنده دارد، اما باید با ظرفیت رزرو شده، قیمت هر توکن، نرخ بهرهبرداری، هزینه برق/خنکسازی و توافق سطح خدمت محصولی سنجیده شود. نسخه عمومی میتواند این بلوغ توان محاسباتی را توضیح دهد؛ نسخه خصوصی باید بودجه GPU، ارائهدهندهها، مصرف هر محصول، زمانبندی آموزش مدل و ریسک تامین را نگه دارد.
مدل-داده آزمایش حلقه: ترکیب، آزمون حذف مولفه و ارزیابی-دروازهدار آموزش مدل
برنامه داده مدل فارسی نباید فقط پیکره داده جمع کند و بعد منتظر معجزه آموزش مدل بماند. باید مدل-داده آزمایش حلقه داشته باشد: هر نسخه پیکره داده با ترکیب دستورالعمل، وزن دامنهها، کیفیت برچسب، میزان مصنوعی داده، حذف رخداد تکراری سطح و نرمالسازی خطمشی ثبت شود؛ سپس مدل یا آداپتور روی ارزیابی فارسی سنجیده شود و مشخص شود کدام داده واقعاً به کدام قابلیت کمک کرده است. بدون این حلقه، تیم نمیفهمد سرمایه داده کجا اثر دارد و کجا فقط حجم اضافه میکند.
آزمون حذف جزء برای فارسی حیاتی است. آیا داده محاورهای به پشتیبانی مشتری کمک کرده یا رسمی استدلال را خراب کرده؟ آیا پیکره داده شعر و داستان روی هذیان مدل فرهنگی اثر دارد؟ آیا OCR نویزدار باعث تحمل خطا شده یا املایی را بدتر کرده؟ آیا داده دامنه تخصصی فروشگاه به بارکد کمک کرده اما مدل عمومی را سوگیری کرده است؟ این سؤالها با احساس جواب داده نمیشوند؛ باید آزمایشهای کوچک، ارزیابیهای ثابت، و دروازه کنترل انتشار نسخههای روشن داشته باشند.
نسخه عمومی میتواند بگوید آپالکسا داده فارسی را با آزمایش، معیارسنجی و دروازه کنترل انتشار نسخه به مدل تبدیل میکند. نسخه خصوصی باید ترکیب دستورالعملها، آزمون حذف مولفه نتایج، آموزش مدل اجراهای آزمایشی، ارزیابی امتیازها، مجموعهداده وزنها، شکست خوشهها، هزینه هر آزمایش و تصمیمهای حذف/افزودن داده را نگه دارد. این بخش نشان میدهد داده برنامه واقعاً برنامه مهندسی مدل است، نه فقط انبار داده.
دیتاستهای دامنهای: فارسی عمومی کافی نیست
مدل فارسی جدی باید فارسی عمومی را با فارسی دامنهای ترکیب کند. زبان فروشگاه با زبان داستان، زبان پشتیبانی با زبان قرارداد، و زبان کشاورزی با زبان مکاتبه اداری فرق دارد. اگر پیکره داده فقط از وب عمومی ساخته شود، مدل در حوزههایی که آپالکسا میخواهد محصول بفروشد ضعیف میماند. بنابراین برنامه داده باید بستههای دامنهای داشته باشد: خردهفروشی و فاکتور، پشتیبانی و شکایت، تماس و رونوشت، آموزش و کودک، داستان و روایت، اسناد سازمانی، کشاورزی، تبلیغات و محتوای برند.
هر دیتاست دامنهای باید هدف روشن داشته باشد. دیتاست خردهفروشی برای فهم کالا، موجودی، قیمت، مالیات، تامینکننده و گزارش فروش است. دیتاست تماس عملیات برای لهجه، قطع جمله، نتیجه تماس و تماس برگشتی است. دیتاست Socheli برای شرح نیاز، متن اجرا، ادعا و برند صدا است. دیتاست Nahid برای روایت، لحن، داستان، فصلبندی و محتوای کودک است. این بستهها به مدل کمک میکنند فقط فارسی روان ننویسد، بلکه در جریانهای کاری واقعی فارسی درست عمل کند.
در نسخه عمومی باید فقط بگوییم برنامه مدل فارسی روی داده دامنهای و کاربردی بنا میشود. نسخه خصوصی باید منبع هر دامنه، مجوز، حجم، کیفیت امتیاز، هزینه پاکسازی، سطح حساسیت، امکان استفاده برای آموزش مدل یا فقط ارزیابی، و مالک محصولی را نگه دارد. این همان جایی است که برنامه مدل از پژوهش عمومی به مزیت دفاعی محصولی تبدیل میشود.
گفتار، OCR و پیکره داده چندرسانهای فارسی
مدل فارسی فقط متن تایپشده نیست. بازار واقعی فارسی پر از صوت، تصویر سند، فاکتور، فرم، پیام صوتی، تماس، ویدئو، اسکن و عکس محصول است. اگر برنامه مدل فارسی فقط روی متن وب تمرکز کند، در Aira تماسها، پشتیبانی، بارکد، ابزارهای سازمانی، Nahid و کشاورزی ضعیف میماند. بنابراین پیکره داده چندرسانهای باید از ابتدا در نقشه باشد: گفتار، OCR، چیدمان، تصویر محصول، رونوشت همراستاسازی و فراداده صوتی.
گفتار فارسی چالشهای خاص دارد: لهجه، نویز تماس، سرعت صحبت، کد-تغییر زبان، نامهای خاص، واژههای صنفی و مکالمههای نیمهتمام. OCR فارسی نیز با فونت، اسکن بد، جدول، فاکتور، مهر، دستنویس، اعداد فارسی/لاتین و ترکیب عربی/فارسی درگیر است. این دادهها باید با رضایت، برچسب، کیفیت و دامنه مجوز وارد شوند. داده صوتی و تصویری حساستر از متن عمومی است و باید پوشاندن داده حساس، دوره نگهداری و دسترسی کنترل جدا داشته باشد.
نسخه عمومی میتواند بگوید مدل فارسی آپالکسا متن، صوت و سند فارسی را باهم میبیند. نسخه خصوصی باید منابع صوت/OCR، نرخ خطا، هزینه رونویسی، برچسب طرحواره، کیفیت ارائهدهندهها، برنامه بهبود گفتار و نویسهخوانی، و محدودیتهای حقوقی داده چندرسانهای را نگه دارد. این بخش برنامه مدل را به محصولات واقعی و پولی آپالکسا وصل میکند.
داده شخصی حساس حذف، حذف حقوقی و داده موضوع داده جریان کار برای داده مدل
برنامه داده فارسی باید برای حذف و اصلاح داده آماده باشد. متن وب، سند سازمانی، رونوشت، صوت، OCR و داده محصولی ممکن است شامل نام، شماره تماس، آدرس، اطلاعات مالی، اطلاعات سلامت یا داده مشتری باشد. قبل از آموزش مدل یا ارزیابی باید داده شخصی حساس تشخیص، پوشاندن داده حساس، نمونهگیری انسانی و خطمشی نگهداری وجود داشته باشد. اگر بعداً صاحب داده یا شریک محتوا درخواست حذف داد، تیم باید بداند کدام مجموعهداده، مدل یا معیارسنجی متاثر میشود.
حذف به درخواست مالک جریان کار باید از همان ابتدا در مجموعهداده دفتر ثبت باشد. هر منبع باید مالک، مجوز، تماس، کاربرد مجاز، دوره نگهداری، هش و پاییندستی مصرف داشته باشد. اگر یک ناشر قرارداد را لغو کرد یا سازمانی گفت دادهاش نباید در ارزیابی بماند، سیستم باید متاثر تقسیم سهمها، بردارهای معنایی، نقاط ذخیره مدل، مجموعههای ارزیابی و محصولهای مصرفکننده را شناسایی کند. این کار سخت است، اما بدون آن برنامه مدل فارسی در مقیاس حقوقی شکننده میشود.
نسخه عمومی میتواند از احترام به مالکیت و حذف داده حرف بزند. نسخه خصوصی باید داده شخصی حساس تشخیص روشها، حذف حقوقی توافق سطح خدمت، متاثر-مدل نگاشت، حذف مدرک، استثنا خطمشی، حقوقی نگهداشتها و هزینه عملیات حذف/بازآموزی را نگه دارد.
تامین داده، شراکت و نردبان مجوز
داده فارسی باکیفیت فقط از خزش/استخراج وب به دست نمیآید. باید مسیرهای تامین داده جدا تعریف شود: داده عمومی مجاز، قرارداد با ناشر و صاحب محتوا، همکاری با دانشگاه و پژوهشگاه، داده عضویت/رضایت فعال از محصولات آپالکسا، دیتاستهای برچسبخورده سفارششده، داده سازمانی برای ارزیابی محدود، و داده مصنوعی که با معیار انسانی کنترل میشود. هر مسیر هزینه، مجوز، ریسک و ارزش متفاوت دارد.
برای هر منبع باید نردبان مجوز وجود داشته باشد. سطح صفر فقط مشاهده و پژوهش داخلی است. سطح یک استفاده برای ارزیابی است. سطح دو استفاده برای بازیابی در همان محیط مشتری است. سطح سه استفاده ناشناسشده برای معیارسنجی یا تنظیم دقیق است. سطح چهار استفاده برای آموزش مدل عمومیتر با قرارداد صریح است. این تفکیک جلوی اشتباه رایج را میگیرد: اینکه تیم فنی هر دادهای را که در دسترس است برای هر هدفی مجاز بداند.
شراکت داده باید برای طرف مقابل هم ارزش داشته باشد. ناشر میتواند ابزار جستوجو، خلاصهسازی و توزیع بهتر بگیرد. دانشگاه میتواند معیارسنجی و انتشار عمومی مشترک بگیرد. سازمان میتواند مدل اختصاصی و گزارش کیفیت دریافت کند. کاربران محصول میتوانند کنترل و خروجیگیری داشته باشند. نسخه عمومی باید فقط اصل شراکت مسئولانه و داده مجاز را منتشر کند؛ نسخه خصوصی باید نام شریکها، شرایط، هزینه، محدودیت انتشار، حجم و مسیر حقوقی را نگه دارد.
پیکره داده سرمایهگذاری مدل، شریک انگیزههای اقتصادی و داده ارزشگذاری
داده فارسی باید مثل سرمایهگذاری دیده شود، نه هزینه پراکنده. هر پیکره داده باید ارزش، هزینه، ریسک و کاربرد داشته باشد: آیا برای آموزش مدل مفید است یا فقط ارزیابی؟ آیا حق استفاده دارد؟ آیا باعث بهبود محصول مشخصی میشود؟ آیا مالک قابل مذاکره دارد؟ آیا پاکسازی و برچسبگذاری آن گران است؟ آیا حساسیت فرهنگی یا حقوقی دارد؟ این مدل کمک میکند برنامه داده به جای جمعآوری هرچیز، سبد پروژه بسازد.
شریک انگیزههای اقتصادی باید روشن باشد. ناشر، دانشگاه، مرکز تماس، فروشگاه، سازمان صنفی، تولیدکننده صوت یا صاحب آرشیو باید بداند در برابر مشارکت داده چه میگیرد: ابزار جستوجو، پاکسازی آرشیو، درآمد سهم، گزارش کیفیت، معیارسنجی مشترک، انتساب، رابط برنامهنویسی اختصاصی یا خدمات داده آمادگی. اگر ارزش فقط برای آپالکسا باشد، مشارکت پایدار نمیشود. اگر ارزش برگشتی واقعی باشد، پیکره داده فارسی به شبکه اعتماد تبدیل میشود.
نسخه عمومی میتواند از شراکت داده مسئولانه، ارزش برگشتی و سرمایهگذاری روی پیکره داده فارسی حرف بزند. نسخه خصوصی باید ارزشگذاری مدل، قیمت جذب، شریک فهرست، مذاکره شرایط، مجوزدهی سطحها، مورد انتظار مدل افزایش، و دفتر خطرها هر پیکره داده را نگه دارد. این بخش برای سرمایهگذار مستقیم است: داده مزیت دفاعی باید قابل ارزشگذاری، قابل دفاع و قابل تکرار باشد.
چرخه عمر داده: ورود داده تا انتشار نسخه
برنامه مدل فارسی باید داده را مثل کد نسخهبندی کند. هر منبع داده از مرحله پیشنهاد وارد میشود، بعد مجوز و حساسیت آن بررسی میشود، سپس ورود داده، نرمالسازی، حذف رخداد تکراری، فیلترکردن، داده شخصی حساس بازبینی، کیفیت امتیازدهی و تقسیم داده برای آموزش مدل/ارزیابی انجام میشود. بدون این چرخه عمر، تیم نمیداند کدام مجموعهداده در کدام مدل استفاده شده و اگر مشکل حقوقی یا کیفیتی پیدا شد چگونه بازگشت کند.
هر مجموعهداده باید شناسنامه داده داشته باشد: منبع، مالک، مجوز، تاریخ، زبان یا گویش، حوزه، سطح نویز، حجم، کاربرد مجاز، محدودیت انتشار و هش نسخه. وقتی مدل جدید انتشار نسخه میشود، باید معلوم باشد دقیقاً از چه دادهای، چه وزندهی و چه دستور/ارزیابی بسته استفاده کرده است. این سطح برای پژوهش شاید سنگین به نظر برسد، اما برای محصول و سرمایهگذار ضروری است.
نسخه عمومی میتواند بگوید آپالکسا فارسی را با خط پردازش داده قابل ممیزی میسازد. نسخه خصوصی باید ابزار مجموعهداده دفتر ثبت، هزینه پاکسازی، شناسنامه داده طرحواره، معیار دروازه کنترل کیفیت و مسئول هر مرحله را نگه دارد.
مجموعهداده انتشار نسخه شناسنامه داده و ردیابی تبار داده برای هر مدل
هر انتشار نسخه مدل فارسی باید انتشار نسخه شناسنامه داده داشته باشد. فهرست داده باید نشان دهد کدام مجموعهدادهها با چه نسخهای استفاده شدهاند، چه دادهای فقط برای ارزیابی بوده، چه دادهای از آموزش مدل حذف شده، چه نرمالسازی قانون فعال بوده، چه برچسب راهنمای استفاده شده، چه مدل پایهای انتخاب شده و چه معیارسنجیهایی پاس یا شکست شدهاند. بدون این سند، تیم بعد از چند ماه نمیداند چرا یک مدل خوب یا بد رفتار میکند.
تبار داده/مدل باید تا سطح محصول هم ادامه پیدا کند. اگر Aira پشتیبانی از یک مدل یا دستور بسته استفاده میکند، باید معلوم باشد آن نسخه از کدام داده پشتیبانی، کدام ارزیابی فارسی، کدام ایمنی دروازه تصمیم و کدام مالک عبور کرده است. اگر در آینده مجموعهدادهی به دلیل حقوقی یا کیفیتی مشکل پیدا کرد، باید بدانیم کدام مدلها و کدام محصولات متاثر هستند. این قابلیت بازگشت و اعتماد را واقعی میکند.
نسخه عمومی میتواند از انتشار مدل با شناسنامه و ممیزی داده حرف بزند. نسخه خصوصی باید شناسنامه داده طرحواره، مجموعهداده هشها، وزندهی، آموزش/ارزیابی تقسیم داده، متاثر-محصول نقشه، بازگشت خطمشی و تصمیمهای تصمیم ادامه/توقف را نگه دارد. این بخش برای سرمایهگذار نشان میدهد برنامه مدل فارسی فقط جمعآوری پیکره داده نیست؛ مهندسی انتشار نسخه قابل ردیابی است.
برچسبگذاری ابزارسازی لایه تامین، بازبین بهرهوری و هزینه-per-کیفیت
برچسبگذاری فارسی بدون ابزارسازی مناسب کند، گران و بیکیفیت میشود. برچسبگذاری لایه تامین باید وظیفههای مختلف را پشتیبانی کند: نیت، لحن، ایمنی، اصلاح، ترجیح جفت، رونوشت پاکسازی، OCR اصلاح، ارجاع منبع کیفیت، گویش/ثبت و چندنوبت انسجام. هر وظیفه باید راهنما، نمونه، داوری اختلاف، کیفیت امتیاز و خروجیگیری قابل استفاده در آموزش مدل/ارزیابی داشته باشد.
هزینه برچسبگذاری را نباید فقط per مورد دید؛ باید هزینه-per-کیفیت سنجیده شود. نمونه ارزان اما پرخطا، مدل و معیارسنجی را خراب میکند. بازبین بهرهوری باید با ابزار بهتر بالا برود: کلیدهای میانبر، تفاوت بازدید، صوت شکل موج، منبع ارجاع منبع، تعارض بازدید، مدل برچسب پیشنهادی اولیه با احتیاط، و نمای مدیریتی توافق. اما کمکگرفته از مدل برچسبگذاری هم باید کنترل شود تا خطای مدل به برچسب رسمی تبدیل نشود.
نسخه عمومی میتواند بگوید آپالکسا برای فارسی کارخانه داده داده و ارزیابی انسانی با کنترل کیفیت میسازد. نسخه خصوصی باید ابزارسازی گزینهها، بازبین توان خروجی، پرداخت بازهها، کنترل کیفیت شاخصها، داوری اختلاف هزینه، خطا نرخها و اتوماسیون برنامه را نگه دارد. این بخش سختترین قسمت برنامه فارسی یعنی عملیات داده را پولی و قابل مدیریت میکند.
سازمان داده و ارزیابی: تیم، ابزار و کیفیت
مدل فارسی با یک تیم فقط پژوهشی ساخته نمیشود. باید تیم داده، تیم زبان، تیم محصول، تیم امنیت داده و تیم ارزیابی کنار هم کار کنند. زبانشناس یا ویراستار فارسی باید با مهندس یادگیری ماشین حرف مشترک داشته باشد. تیم محصول باید خطاهای واقعی Aira، بارکد، پشتیبانی، Nahid و Socheli را به معیارسنجی تبدیل کند. تیم حقوقی یا حاکمیت باید منبع داده و مجوز را کنترل کند.
ابزار داخلی هم لازم است: برچسبگذاری کنسول مدیریتی، بازبینی صف، طلایی بسته مدیر، مجموعهداده تفاوت، معیارسنجی اجراکننده، مدل مقایسه نمای مدیریتی و خطا طبقهبندی. اگر این ابزارها نباشند، کیفیت به حافظه افراد وابسته میشود. برنامهای که میخواهد «فارسی جدی» بسازد باید بتواند نشان دهد چرا یک نسخه از مدل بهتر از نسخه قبل است، نه اینکه فقط چند نمونه خروجی بهتر ارائه کند.
از نظر سرمایهگذاری، این بخش هزینه دارد اما مزیت دفاعی میسازد. رقبا ممکن است مدل متنباز را اجرا کنند، اما ساختن داده، معیار داوری، معیارسنجی و تیم ارزیابی فارسی زمان و انباشت عملی میخواهد. نسخه خصوصی باید بودجه تیم، ظرفیت برچسبگذاری، ابزار نقشه راه و نقطه عطف کیفیت را دقیق نگه دارد.
ارزیاب کالیبراسیون، داوری اختلاف و کنترل سوگیری فارسی
کیفیت برچسب و ارزیابی فقط به تعداد ارزیاب بستگی ندارد؛ به کالیبراسیون بستگی دارد. ارزیابها باید نمونههای مرزی ببینند، معیار داوری مشترک داشته باشند، اختلافشان اندازهگیری شود و برای موارد سخت داوری اختلاف وجود داشته باشد. اگر یک ارزیاب لحن رسمی را خوب بداند و دیگری همان پاسخ را خشک یا نامناسب بداند، معیارسنجی به صدا تبدیل میشود.
سوگیری فارسی باید صریح دیده شود. داده و ارزیابی ممکن است به نفع یک ثبت، منطقه، طبقه، سطح سواد، جنسیت زبانی، یا سبک رسمی خاص کجی/انحراف شود. برنامه باید پوشش و انصاف عملیاتی داشته باشد: آیا مدل در پیام محاورهای، لهجه، متن کودک، سند اداری، فروش محلی و محتوای فرهنگی به شکل متوازن عمل میکند؟ هدف ساخت مدل سیاسی یا عمومی نیست؛ هدف جلوگیری از کیفیت کاذب در یک نوع فارسی و شکست در کاربردهای واقعی است.
نسخه عمومی میتواند از ارزیابی انسانی کالیبرهشده و پوشش انواع فارسی صحبت کند. نسخه خصوصی باید ارزیاب استخر عرضه، توافق امتیازها، داوری اختلاف جریان کار، سوگیری ممیزی، نمونهگیری برنامه، هزینه کنترل کیفیت و شناختهشده شکافها را نگه دارد. این بخش مکمل کارخانه داده و دروازه کنترل انتشار نسخه است.
آزمایشگاه ارزیابی و دروازه کنترل انتشار نسخه فارسی
هر نسخه مدل یا بسته تنظیم دقیق باید از دروازه کنترل انتشار نسخه عبور کند. دروازه کنترل انتشار نسخه یعنی قبل از استفاده در Aira، پشتیبانی، بارکد یا ابزار سازمانی، مدل روی مجموعهای از تستهای فارسی، ایمنی، دامنهای و اقتصادی سنجیده شود. تستها باید فقط چند دستور نمایشی نباشند؛ باید شامل طلایی بسته، خصمانه بسته، مکالمات چندمرحلهای، سناریوهای حذف داده، ارجاع منبع، لحن رسمی/محاورهای، نیمفاصله، تاریخ جلالی و پاسخ به موضوعات حساس باشند.
آزمایشگاه ارزیابی باید خطاها را طبقهبندی کند: هذیان مدل، لحن غلط، منبعسازی، بیدقتی عددی، فراموشی دستور، استفاده نامناسب از حافظه، ضعف اصطلاحات دامنه، خروجی بیش از حد انگلیسیزده، و خطای ایمنی. هر خطا باید شدت و مالک داشته باشد. اگر مدل در کار عمومی بهتر شد اما در پشتیبانی مشتری خطای تعهد حقوقی داد، نباید وارد آن محصول شود. این سطح از نظم مهندسی برای سرمایهگذار نشان میدهد مدل فارسی فقط یک ادعا نیست.
نسخه عمومی میتواند از ارزیابی چندلایه و دروازه کنترل انتشار نسخه فارسی صحبت کند. نسخه خصوصی باید معیارسنجیها، دستورها، خطاهای شناختهشده، آستانهها، مدلهای مقایسه، هزینه استنتاج در ارزیابی و تصمیمهای تصمیم ادامه/توقف را نگه دارد. این دادهها هم مزیت فنیاند و هم اگر خام منتشر شوند میتوانند سوءبرداشت یا سوءاستفاده بسازند.
چرا این برنامه برای آپالکسا طبیعی است
آپالکسا از بیرون شاید مجموعهای از محصولات متفاوت به نظر برسد؛ اما از داخل، همین تنوع منبع مزیت دادهای و کاربردی است. Aira تجربهی مصرفی فارسی را میسازد. بارکد با داده و واژگان کسبوکار ایرانی درگیر است. Aira پشتیبانی و فروش زبان عملیات مشتری و فروش را میشناسند. Socheli با تولید محتوای عاملمحور، نیاز به لحن، روایت و حافظهی برند دارد. Nahid سطح فرهنگی و داستانی فارسی را به اکوسیستم اضافه میکند. Wharf و MoltJobs نشان میدهند این مدل فقط برای گفتوگو نیست؛ برای اقتصاد نرمافزار و عاملها نیز باید قابل استفاده باشد.
بنابراین برنامهی مدل فارسی برای آپالکسا یک پروژه جداگانه نیست. این برنامه میتواند هستهی مشترک همهی محصولات باشد. هر محصول یک مدرک سطح تعامل است: مکانی که مدل در آن با مسئله واقعی، کاربر واقعی، داده واقعی و هزینه واقعی روبهرو میشود. همین تفاوت میان پژوهش نمایش اولیه و زیرساخت زنده است.
نسخهی عمومی این مقاله باید جهانبینی را توضیح دهد. نسخهی سرمایهگذار باید نقشهی پول، تیم، داده، هزینه توان محاسباتی، زمانبندی، معیارسنجی، محصولهای اولیه و مسیر درآمد را باز کند. نسخهی داخلی باید عملیاتی باشد: چه دادهای داریم، چه دادهای نداریم، چه چیزی حساس است، چه چیزی قابل انتشار است، و هر فصل از مدلسازی چگونه به محصول وصل میشود.
گالری تصویر تولیدی
برای هر سند، تصاویر تولیدی و دستورهای تصویرسازی کنار هم نگه داشته میشوند تا نسخه عمومی و نسخه سرمایهگذار قابل گسترش باشند.
کارگاه دادهی فارسی
تصویر فرایند: نمای «کارگاه دادهی فارسی» برای توضیح مسیر اجرای «برنامهی مدل بنیادین و دادهی فارسی». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیمدل فارسی در لایهها
تصویر فرایند: نمای «مدل فارسی در لایهها» برای توضیح مسیر اجرای «برنامهی مدل بنیادین و دادهی فارسی». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیزبان و هویت
تصویر فرایند: نمای «زبان و هویت» برای توضیح مسیر اجرای «برنامهی مدل بنیادین و دادهی فارسی». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیمحصولات مرتبط و منابع
منابع پایین، نقطه شروع تحقیق عمیقترند؛ برای نسخه نهایی هر مقاله باید منابع بیشتری اضافه شود.