هوش مصنوعی فارسی ترجمه نیست
مقالهای درباره اینکه تجربه فارسی باید از داده، دستور زبان، واژگان، فرهنگ، صوت و رابط کاربری شروع شود، نه از ترجمه خروجی انگلیسی.

تز مرکزی
مدلی که فارسی را فقط بیان میکند، الزاماً فارسی فکر نمیکند.
آنچه عمومی میماند
مقاله عمومی برای توضیح چرایی مدل/داده فارسی و محصولات فارسیمحور.
- تز عمومی: تجربه فارسی جدی از پیکره داده، نیمفاصله، دستور زبان، لحن، گویش، صوت، فرهنگ، UI و معیارسنجی فارسی شروع میشود.
- نقشه عمومی برنامه: داده فارسی، ارزیابی فارسی، صدا، محصول فارسیمحور، هویت محتوایی و اتصال به Aira، بارکد، Nahid و CognitivX.
- مرز عمومی با برنامه مدل فارسی: باید توضیح دهد چرا ترجمه خروجی انگلیسی کافی نیست و چرا داده/برچسبگذاری فارسی سختترین قسمت است.
آنچه در اتاق سرمایهگذار/داخلی میماند
استراتژی داده، بنچمارکهای اختصاصی و منابع پیکره داده.
- منابع پیکره داده، قرارداد داده، کیفیت/هزینه برچسبگذاری، معیارسنجیهای اختصاصی، داده صوتی، خط پردازش نرمالسازی و مدلهای انتخابی.
- داده محصولی Aira/بارکد/Nahid، خطاهای مدل، دستور/مجموعههای ارزیابی، سیاست ایمنی، تامینکننده مسیریابی و مزیتهای مجموعهداده.
- بودجه توان محاسباتی، تیم داده، برنامه آموزش مدل/ظریف-تنظیم دقیق، مجوزدهی ریسک، قراردادهای محتوا و نقشه انتشار پژوهشی/خصوصی.
معماری و نقشه اجرا
این بخش برای تبدیل هر ایده به مقالهی بلند، یادداشت سرمایهگذار و نقشهی اجرایی استفاده میشود.
معماری
- فارسی پیکره داده
- توکنسازی
- معیارسنجیها
- صدا
- فرهنگ
- محلی UX
نقشه راه
- مقاله
- بنچمارک
- داده
- مدل
- محصول
طرح مقالهی بلند
هدف هر سند، مقالهای حداقل ۱۰هزار واژهای با منابع و نسخهی عمومی/خصوصی جداست.
ترجمهمحوری
دستور زبان
واژگان محلی
هویت
داده و برچسب
بنچمارک
کاربردها
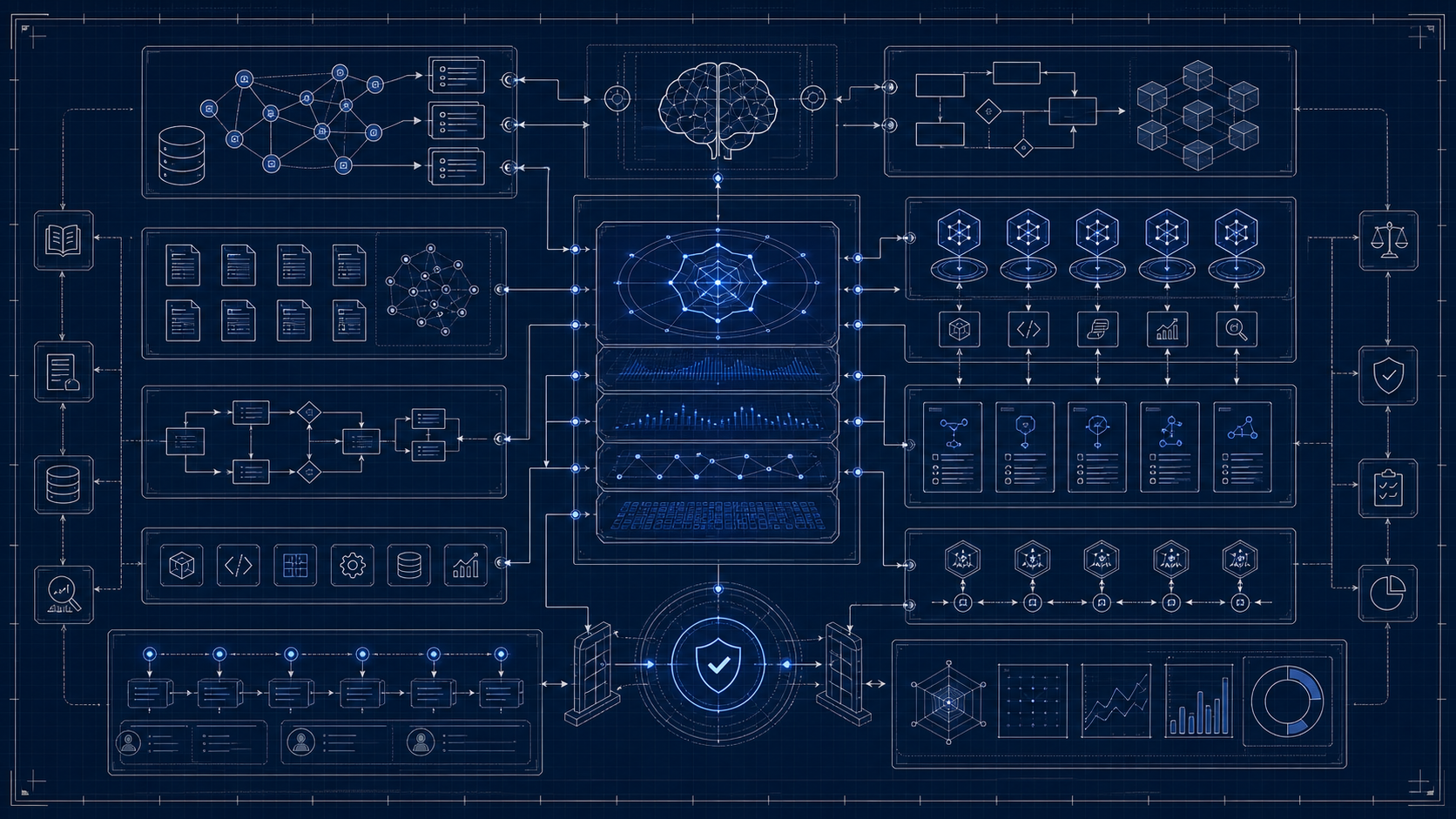
بلوپرینت مقاله
مدلی که فارسی را فقط بیان میکند، الزاماً فارسی فکر نمیکند.
نقشه تصویری فرایند
این تصاویر در میانهی خواندن سند، مسیر اجرا، معماری و نقاط تصمیم را ملموستر میکنند؛ نسخهی کاملتر هر تصویر در گالری پایین صفحه نگهداری میشود.


پیشنویس مقاله
این متن نسخهی نخست مقالهی بلند «هوش مصنوعی فارسی ترجمه نیست» است. تمرکز آن روی تفاوت فارسیگویی سطحی با فارسیفهمی واقعی، داده، نیمفاصله، لحن، صوت، معیارسنجی و هویت محصولی فارسی است.
دام ترجمهمحوری
بخش بزرگی از تجربههای فارسی امروز در هوش مصنوعی، ترجمه تجربه انگلیسی است. مدل مسئله را با منطق داده و فرهنگ انگلیسی یاد گرفته، سپس خروجی فارسی تولید میکند. نتیجه میتواند روان باشد اما همچنان بیگانه بماند: لحن نامناسب، اصطلاح غلط، نادیده گرفتن نیمفاصله، اشتباه در تاریخ جلالی، ضعف در مکاتبه اداری، یا پاسخهایی که برای زندگی ایرانی دقیق نیستند.
ترجمه نقطه شروع مفید است، اما مقصد نیست. هوش مصنوعی فارسی باید در داده فارسی، برچسبگذاری فارسی، سناریوهای فارسی، صوت فارسی و UI فارسی ریشه داشته باشد. مدلی که فارسی را فقط بیان میکند، الزاماً فارسی فکر نمیکند. این جمله باید تز اصلی مقاله باشد.
برای آپالکسا، این بحث نظری نیست. Aira، بارکد، Nahid، Aira پشتیبانی، فروش و برنامه ANI همگی به فارسی عمیق نیاز دارند. اگر هسته زبانی سطحی باشد، همه محصولات در لحظههای مهم کیفیتشان را از دست میدهند.
فارسی جزئیات فنی خودش را دارد
فارسی فقط مجموعهای از واژهها نیست. نیمفاصله، شکل حروف، اعداد فارسی و لاتین، ترکیب عربی و فارسی، فینگلیش، لحن رسمی و محاورهای، شعر و ادبیات، گویشها، واژههای بازاری، فرمهای اداری، اصطلاحات حقوقی و مکالمههای خانوادگی، همه روی تجربه مدل اثر میگذارند. مدل عمومی اگر این جزئیات را در داده و ارزیابی ندیده باشد، خطاهای ظریف اما مهم تولید میکند.
در محصول، این خطاها آزاردهندهتر میشوند. پشتیبانی مشتری باید همدلانه اما دقیق باشد. ابزار حسابداری باید اصطلاحات مالی ایران را بفهمد. دستیار کشاورزی باید زبان زمین و آب را بداند. پلتفرم داستان باید لحن روایت فارسی را حفظ کند. حتی یک ابزار ساده نوشتن پیام باید تفاوت بین رسمی، محترمانه، دوستانه و محکم را در فارسی تشخیص دهد.
بنابراین برنامه فارسی باید از نرمالسازی و توکنسازی تا معیارسنجی و UX را پوشش دهد. این سطح عمومی قابل انتشار است؛ اما خط پردازش دقیق داده و ارزیابی باید خصوصی بماند.
کاربردشناسی زبان، تعارف و نیت فارسی
یکی از خطاهای پنهان مدلهای ترجمهمحور این است که معنی لغوی را میفهمند اما نیت اجتماعی جمله را نه. فارسی روزمره و اداری پر از تعارف، کنایه ملایم، رد غیرمستقیم، احترام، فاصله اجتماعی، دعوت ظاهری، درخواست نرم، و جملههایی است که بدون زمینه کامل فهمیده نمیشوند. کاربر ممکن است بگوید «زحمت نمیدهم» اما واقعاً انتظار پیگیری داشته باشد؛ مشتری ممکن است بگوید «فعلاً بررسی میکنیم» و معنی آن رد مودبانه باشد؛ مدیر ممکن است با جمله کوتاه، دستور جدی بدهد. مدل فارسی باید این لایه نیت را در محصول بفهمد.
این موضوع فقط زیبایی زبانی نیست؛ روی فروش، پشتیبانی، آموزش، سلامت تعامل و اعتماد اثر مستقیم دارد. Aira پشتیبانی اگر شکایت مودبانه را بهعنوان رضایت بخواند، پاسخ اشتباه میدهد. Aira فروش اگر تعارف مشتری را سرنخ گرم فرض کند، خط پردازش را خراب میکند. دستیار سازمانی اگر لحن سلسلهمراتبی مکاتبه فارسی را نفهمد، پیشنهاد نامناسب میدهد. حتی تولید داستان و کتاب صوتی هم بدون کاربردشناسی زبان فارسی، مصنوعی و بیروح میشود.
نسخه عمومی مقاله باید توضیح دهد که فارسیفهمی یعنی فهم نیت، ادب، فاصله و بافت، نه فقط تولید جمله روان. نسخه خصوصی باید مجموعه مثالهای واقعی، معیار داوری تشخیص نیت، دستورهای ارزیابی، موارد حساس و نتیجه آزمون تهاجمی را نگه دارد. این بخش برای سرمایهگذار مهم است چون نشان میدهد مزیت دفاعی فارسی آپالکسا فقط پیکره داده نیست؛ فهم رفتار زبانی و اجتماعی فارسی است.
داده و برچسبگذاری، سختترین قسمتاند
معماری مدل مهم است، اما داده فارسی باکیفیت تعیینکننده است. داده وب پر از نویز، کپی، خطای OCR، متن تبلیغاتی، محتوای قدیمی، ترکیب عربی و فارسی و اطلاعات حساس است. اگر این داده بدون پاکسازی و وزندهی وارد مدل شود، مدل همان آشفتگی را یاد میگیرد. داده خوب باید پاک، متنوع، مجاز، برچسبخورده و قابل تکرار باشد.
برچسبگذاری فارسی نباید فقط ترجمه دستورهای انگلیسی باشد. باید سناریوهای واقعی فارسی ساخته شود: فروشگاه، مدرسه، اداره، پیام خانوادگی، پشتیبانی مشتری، مکاتبه رسمی، داستان، صوت، کشاورزی، مالیات و سلامت. برچسبگذار باید بداند پاسخ خوب فارسی فقط درست نیست؛ طبیعی، متناسب، ایمن و بافتمند است.
این همان قسمت پرهزینه و سخت است که باید در پیشنهاد سرمایهگذار باز شود. نسخه عمومی میتواند اهمیت داده را توضیح دهد؛ نسخه خصوصی باید منابع پیکره داده، هزینه لیبلینگ، حقوق محتوا، خط پردازش و معیارسنجیهای اختصاصی را نگه دارد.
عملیات برچسبگذاری و آموزش ارزیاب فارسی
برچسبگذاری فارسی اگر فقط به پیمانکار ارزان سپرده شود، کیفیت مدل را خراب میکند. باید راهنمای برچسبگذاری، مثال خوب و بد، تست ورود ارزیاب، بازبینی چندلایه، طلایی بسته، بین-برچسبگذار توافق و مسیر بازخورد وجود داشته باشد. فارسی خوب فقط معنی درست نیست؛ لحن، ادب، طبیعی بودن، نیمفاصله، زمینه فرهنگی و پرهیز از ادعای خطرناک هم هست.
برای هر حوزه باید دستورالعمل جدا نوشت. پشتیبانی مشتری معیارهای خودش را دارد؛ داستان و کتاب صوتی معیار خودش را دارد؛ فاکتور و کالای فروشگاه معیار خودش را دارد؛ مکاتبه اداری معیار خودش را دارد. اگر همه را با یک معیار داوری عمومی بسنجیم، مدل در هیچ حوزهای عمیق نمیشود.
این عملیات میتواند با محصولات آپالکسا تغذیه شود اما باید حقوق و رضایت داشته باشد. نسخه عمومی باید بگوید فارسی جدی نیازمند داده نیروی کار جدی است. نسخه خصوصی باید نرخ پرداخت ارزیاب، ساختار کنترل کیفیت، طلایی مجموعهها، خطاهای رایج و هزینه هر هزار نمونه را نگه دارد.
دستورالعمل تنظیم دقیق، ترجیح داده و همراستاسازی فارسی
مدل فارسی جدی فقط با متن خام بهتر نمیشود. باید دستور داده و ترجیح داده فارسی داشته باشد: کاربر چه میخواهد، پاسخ خوب چه ویژگی دارد، پاسخ بد چرا بد است، کجا باید سوال روشنکننده پرسید، کجا باید محتاط بود، کجا لحن رسمی لازم است و کجا پاسخ کوتاه و محاورهای بهتر است. ترجمه مجموعهدادههای انگلیسی این لایه را کامل نمیسازد، چون نیت و ادب فارسی رفتار متفاوتی دارند.
ترجیح داده باید دامنه تخصصی-آگاه باشد. در پشتیبانی مشتری، پاسخ خوب باید همدلانه، دقیق و اقدام-محور باشد. در مکاتبه اداری، ادب و ساختار مهم است. در خانواده و آموزش، ایمنی و زبان قابل فهم مهمتر است. در ابزار سازمانی، ارجاع منبع، محدودیت داده و پرهیز از حدس تعیینکننده است. این دادهها باید با جفتبهجفت مقایسه، معیار داوری، بازبین کالیبراسیون و اختلاف نظر بازبینی ساخته شوند.
نسخه عمومی میتواند توضیح دهد که فارسیسازی عمیق یعنی ساخت داده ترجیح و دستور فارسی، نه فقط تنظیم دقیق روی متن. نسخه خصوصی باید دستورها، ترجیح جفتها، معیار داوریها، بازبین استخر عرضه، هزینه نمونه، مدل مسیریابی، داده حقوق و نتایج همراستاسازی ارزیابی را نگه دارد.
بنچمارک فارسی باید فراتر از ترجمه باشد
اگر مدل فارسی فقط با وظیفههای ترجمه یا پرسش عمومی سنجیده شود، ضعفهای واقعی پنهان میماند. معیارسنجی باید دستور زبان، نیمفاصله، لحن، دانش محلی، فرمهای اداری، استدلال، ایمنی، حریم خصوصی، گویش، صوت و کاربردهای محصولی را بسنجد. یک مدل ممکن است در جواب عمومی خوب باشد اما در پاسخ به مشتری ناراضی، فاکتور فروشگاه یا روایت داستانی ضعیف عمل کند.
آپالکسا میتواند از محصولاتش برای ساخت معیارسنجی استفاده کند. بارکد سناریوهای کالا، قیمت و انبار میدهد. Aira پشتیبانی زبان پشتیبانی و شکایت میدهد. Nahid روایت و صوت میدهد. Socheli لحن برند و محتوا میدهد. CognitivX تعامل بلندمدت و حافظه میدهد. این ترکیب میتواند معیارسنجیهایی بسازد که هم پژوهشیاند و هم به محصول وصلاند.
نسخه عمومی باید معیارسنجی را بهعنوان ضرورت علمی و محصولی معرفی کند. نسخه خصوصی باید آزمون بستهها، خطاهای مدل، امتیازهای واقعی و برنامه بهبود را نگه دارد.
طبقهبندی خطاهای فارسی و مدل کارت محلی
برای بهتر کردن فارسی، فقط امتیاز کلی کافی نیست. باید طبقهبندی خطا داشته باشیم: نیمفاصله، واژه عربی/فارسی، لحن نامناسب، ترجمهزدگی، تاریخ جلالی، عدد و واحد، اصطلاح صنفی، هذیان مدل محلی، پاسخ بیش از حد رسمی، پاسخ بیش از حد صمیمی، ضعف گویش، و ناتوانی در مکالمه چندنوبتی. وقتی خطاها دستهبندی شوند، تیم میفهمد مشکل از داده، مدل، دستور، بازیابی، UI یا ارزیابی است.
هر مدل یا بسته دستور باید مدل کارت محلی داشته باشد: برای چه کاربرد فارسی مناسب است، کجا ضعیف است، روی چه معیارسنجیهایی سنجیده شده، چه دادههایی مجاز بوده، چه محدودیت حقوقی دارد، هزینه استنتاج چقدر است و چه حفاظ تصمیمهایی لازم دارد. این مدل کارت باید برای تیم محصول قابل فهم باشد، نه فقط برای پژوهشگر یادگیری ماشین.
نسخه عمومی میتواند بگوید آپالکسا کیفیت فارسی را با دستهبندی خطا و مدل کارت میسنجد. نسخه خصوصی باید طبقهبندی کامل، نمونه خطاها، امتیاز مدلها، شکستهای شناختهشده، دستور/مدل مسیریابی و تصمیمهای انتشار نسخه را نگه دارد.
ارزیابی شکست خوشهها و جبران و اصلاح فهرست کارهای مانده فارسی
معیارسنجی زمانی ارزش دارد که شکستها به فهرست کارهای مانده قابل اجرا تبدیل شوند. اگر مدل در تاریخ جلالی، نیمفاصله، لحن رسمی/محاورهای، نامهای ایرانی، واحد پول، ارجاع به منبع، گویش، تعارف، یا پاسخ به مشتری ناراضی خطا میکند، این نباید فقط در یک گزارش بماند. هر شکست خوشه باید مالک، شدت، محصول متاثر، داده لازم، جبران و اصلاح مسیر و دروازه کنترل انتشار نسخه داشته باشد. فارسی جدی با نمره کلی ساخته نمیشود؛ با چرخه منظم کشف خطا و اصلاح ساخته میشود.
اصلاح/ترمیم میتواند چند شکل داشته باشد: نرمالسازی بهتر، توکنساز یا پیشپردازشگر، داده برچسبخورده جدید، دستور سبک قانون، بازیابی پیکره داده مجاز، تنظیم دقیق محدود، حفاظ تصمیم دامنهای، UI متن رابط، یا آموزش ارزیاب. برای مثال، مشکل لحن در پشتیبانی مشتری شاید با مدل بزرگتر حل نشود؛ ممکن است به معیار داوری پاسخ، مثالهای فارسی و ارجاع انسانی نیاز داشته باشد. مشکل هذیان مدل محلی شاید با بازیابی و ارجاع منبع بهتر حل شود، نه با آموزش مدل گستردهتر.
نسخه عمومی میتواند توضیح دهد آپالکسا کیفیت فارسی را با شکست طبقهبندی و اصلاح مرحلهای اداره میکند. نسخه خصوصی باید خطاهای واقعی، مجموعهداده نمونه، فهرست کارهای مانده جبران و اصلاح، مالکها، امتیازهای مدل، انتشار نسخه آستانهها، و تصمیمهای فنی مثل مدل مسیریابی یا تنظیم دقیق را نگه دارد. این بخش برای سرمایهگذار نشان میدهد برنامه فارسی یک شعار فرهنگی نیست؛ سیستم کیفیت و محصول دارد.
فرهنگی/حقوقی آزمون تهاجمی هیات راهبری و زمینه حساس بازبینی فارسی
فارسیفهمی جدی باید در بافتهای حساس فرهنگی و حقوقی آزمون تهاجمی شود. برخی خطاها فقط «اشتباه زبانی» نیستند: نسبت دادن نقلقول نادرست، سوءبرداشت از تعارف، پاسخ سیاسی بیاحتیاط، توصیه پزشکی/حقوقی قطعی، برخورد بد با دین یا هویت فرهنگی، یا استفاده از واژهای که در یک ثبت خاص توهینآمیز است. این خطاها باید قبل از انتشار نسخه در زمینه حساس بازبینی دیده شوند.
آزمون تیم قرمز هیات راهبری میتواند ترکیبی از زبانشناس، حقوقدان، متخصص ایمنی، بازبین محصول و افراد آشنا با دامنههای فارسی باشد. وظیفه آن سانسور عمومی نیست؛ وظیفهاش شناخت ریسک و طراحی پاسخ مسئولانه است. برای هر دامنه باید سناریوهای تست، خطمشی، ارجاع و ارجاع منبع نیازمندی تعریف شود. اگر مدل مطمئن نیست، باید مرز دانش را روشن کند یا به انسان/منبع معتبر ارجاع دهد.
نسخه عمومی میتواند بگوید آپالکسا مدل فارسی را در زمینههای حساس با آزمون تهاجمی، انسان متخصص و دروازه کنترل انتشار نسخه ارزیابی میکند. نسخه خصوصی باید سناریوهای آزمون تهاجمی، افراد/نقشها، معیار داوریها، شکست نمونهها، حقوقی بازبینی و تصمیمهای انتشار نسخه را نگه دارد. این بخش به تز فارسی عمق اجتماعی و محصولی میدهد.
ایمنی فارسی در دامنههای حساس
فارسیفهمی جدی بدون ایمنی فارسی ناقص است. دامنههایی مثل سلامت، حقوق، مالی، آموزش کودک، دین، سیاست، شایعه، بحران و توصیههای پرریسک در فارسی الگوهای خاص خود را دارند. مدل عمومی ممکن است یک خطمشی انگلیسی را ترجمه کند، اما در عمل نداند چه واژهای در فارسی ادعای قطعی پزشکی محسوب میشود، چه عبارتی مشاوره حقوقی خطرناک است، یا چه نوع شایعه محلی باید با احتیاط و ارجاع به منبع پاسخ داده شود.
این ایمنی باید محصولی باشد، نه فقط لایهای از ممنوعیت. پاسخ خوب فارسی در حوزه حساس باید مرز دانش را روشن کند، کاربر را تحقیر نکند، به متخصص یا مرجع مناسب ارجاع دهد، از نسخه دادن پرهیز کند، و اگر سیستم برای یک سازمان کار میکند، به خطمشی همان سازمان احترام بگذارد. برای ANI، ابزار داخلی، پشتیبانی مشتری و دستیار کشاورزی، این موضوع پایه اعتماد است. خطای ایمنی در فارسی فقط خطای مدل نیست؛ خطای برند و حاکمیت است.
نسخه عمومی میتواند اصول ایمنی فارسی را منتشر کند: احتیاط، ارجاع منبع، انسانی ارجاع، محدودیت دامنه و شفافیت. نسخه خصوصی باید ایمنی ارزیابی بسته، مثالهای آزمون تهاجمی، ارجاع قوانین، دستورهای طبقهبندی ریسک، خطاهای شناختهشده و خطمشیهای دامنهای را نگه دارد. این تفکیک اجازه میدهد آپالکسا مسئولانه حرف بزند بدون اینکه راهنمای اجرا دفاعی خود را عمومی کند.
هویت فارسی در UI و صوت هم ساخته میشود
حتی اگر مدل زبانی بهتر شود، تجربه فارسی بدون UI و صوت خوب کامل نیست. راستبهچپ، فونت، اعداد، تاریخ، کپیرایتینگ، پیام خطا، حالت رسمی/محاورهای، صدا تعامل و دسترسپذیری همه بخشی از هوش مصنوعی فارسیاند. محصولی که فقط متن فارسی تولید میکند اما UI انگلیسیمحور دارد، هنوز محلی نشده است.
صوت اهمیت خاص دارد. بسیاری از کاربران فارسی با گفتار طبیعیتر از تایپ طولانی کار میکنند. اما صوت فارسی با لهجه، نویز، سرعت، نامهای خاص و کد-تغییر زبان درگیر است. اگر Aira یا ابزار سازمانی بخواهد واقعاً روزمره شود، تبدیل گفتار به متن، تبدیل متن به گفتار و دیالوگ صوتی باید جزو برنامه اصلی باشند.
هویت فارسی همچنین شامل فرهنگ و ادب گفتگوست. مدل باید بداند کجا مستقیم باشد، کجا محتاط، کجا گرم، کجا رسمی، و کجا باید از ادعای قطعی پرهیز کند. اینها با ترجمه حل نمیشوند؛ با داده، ارزیابی و طراحی محصول حل میشوند.
سبکنامه فارسی محصولی و یکپارچگی بین محصولات
فارسی عمیق فقط در مدل نیست؛ در سبکنامه محصولی هم هست. Aira، بارکد، Nahid، Socheli، پشتیبانی و فروش نباید هرکدام لحن و واژگان جدا و تصادفی داشته باشند. باید سبکنامه فارسی آپالکسا تعریف شود: چه زمانی رسمی باشیم، چه زمانی محاورهای، چطور خطا را توضیح دهیم، چطور به کاربر عصبانی جواب دهیم، چطور از واژههای انگلیسی استفاده کنیم، اعداد و تاریخ را چگونه بنویسیم، و چه اصطلاحاتی برای هر محصول استاندارد است.
این سبکنامه باید به دستورها، UI متن رابط، پیام خطا، ورود مشتری، پاسخهای هوش مصنوعی، مستندات و پشتیبانی وصل شود. اگر مدل پاسخ خوبی بدهد اما UI و پیامهای سیستم ناهمگون باشند، تجربه فارسی همچنان ضعیف است. سبکنامه همچنین به برچسبگذاری و ارزیابی کمک میکند؛ ارزیاب میداند پاسخ خوب فقط درست نیست، با شخصیت محصول و مخاطب هم هماهنگ است.
نسخه عمومی میتواند اصل فارسی-محور محصول زبان را منتشر کند. نسخه خصوصی باید واژهنامه، مثالهای خوب/بد، دستور قواعد سبک، لحن ماتریس، اصطلاحات صنفی و تستهای یکپارچگی را نگه دارد. این بخش مزیت نرم اما مهمی برای برند و دوره نگهداری است.
داده فارسی باید قرارداد حقوقی و کیفی داشته باشد
داده فارسی فقط از نظر فنی سخت نیست؛ از نظر حقوقی و کیفی هم سخت است. متن کتاب، مقاله، خبر، پیام، سند سازمانی، گفتوگو، صوت و محتوای کاربر هرکدام مالکیت و حساسیت متفاوت دارند. اگر برنامه فارسی بدون قرارداد داده پیش برود، هم به ریسک حقوقی میرسد و هم اعتماد شرکای محتوا را از دست میدهد.
هر مجموعهداده باید شناسنامه داشته باشد: منبع، مجوز، تاریخ، نوع متن، کیفیت، زبان/گویش، حساسیت، مجاز بودن برای آموزش مدل یا ارزیابی، و محدودیت انتشار. این شناسنامه از همان ابتدا باید بخشی از خط پردازش باشد. مجموعهداده بدون شناسنامه شاید برای آزمایش کوتاهمدت مفید باشد، اما برای محصول و سرمایهگذار قابل دفاع نیست.
نسخه عمومی میتواند اصل حقوق داده و کیفیت را توضیح دهد. نسخه خصوصی باید منابع پیکره داده، قراردادها، دفتر خطرها، قیمت جذب، و تصمیمهای مجوز را نگه دارد.
کارخانه داده فارسی: گردآوری، پاکسازی، برچسبگذاری کنترل کیفیت
برنامه فارسی جدی به کارخانه داده نیاز دارد، نه جمعآوری پراکنده فایل. کارخانه داده یعنی خط پردازش مشخص برای کشف منبع، بررسی حق استفاده، ورود داده، پاکسازی، نرمالسازی، حذف رخداد تکراری، طبقهبندی دامنه، برچسبگذاری، کنترل کیفیت، نسخهبندی و ثبت ردیابی تبار داده. هر مجموعهداده باید بداند از کجا آمده، چه چیزی حذف شده، چه کسی برچسب زده، چه کیفیتی دارد و برای کدام کاربرد مجاز است.
برچسبگذاری کنترل کیفیت سختترین قسمت است. برچسب نیت فارسی، لحن، تعارف، ایمنی، خطای صوت، سند اداری یا روایت داستانی با ترجمه ساده ساخته نمیشود. باید راهنمای ارزیاب، نمونههای مرزی، دوگانه/دوباره بازبینی، داوری اختلاف و اندازهگیری توافق وجود داشته باشد. اگر برچسبها بیکیفیت باشند، مدل و معیارسنجی هر دو با اعتماد کاذب ساخته میشوند.
نسخه عمومی میتواند بگوید آپالکسا برای فارسی خط پردازش داده مسئولانه و باکیفیت میسازد. نسخه خصوصی باید منبع خط پردازش، مجوز وضعیت، برچسبگذاری دستورالعملها، بازبین استخر عرضه، کنترل کیفیت شاخصها، هزینه هر نمونه، شناختهشده سوگیری و مجموعهداده نسخهبندی را نگه دارد. این بخش مستقیماً به مقاله مدل بنیادین فارسی و ANI وصل است.
داده مجوزدهی هیات راهبری و ارزش پیشنهادی برای صاحبان محتوا
برنامه فارسی جدی نمیتواند فقط مصرفکننده خام داده باشد؛ باید برای صاحبان محتوا ارزش بسازد. ناشر، دانشگاه، رسانه، تولیدکننده صوت، سازمان صنفی یا صاحب آرشیو باید بداند چرا همکاری با آپالکسا به نفع اوست: جستوجوی بهتر، خلاصهسازی کنترلشده، ابزار آرشیو، گزارش کیفیت، درآمد سهم، معیارسنجی مشترک یا حفظ میراث زبانی. اگر داده فقط گرفته شود و ارزش برنگردد، همکاری پایدار نمیشود.
داده مجوزدهی هیات راهبری میتواند تصمیمهای مجوز را استاندارد کند. هر منبع باید مسیر تایید کردن داشته باشد: استفاده فقط برای ارزیابی، استفاده برای بازیابی در همان محیط مشتری، استفاده ناشناسشده برای معیارسنجی، استفاده برای تنظیم دقیق محدود، یا استفاده برای آموزش مدل گستردهتر با قرارداد صریح. هیات راهبری باید حقوق، کیفیت، حساسیت فرهنگی، ریسک اعتباری و ارزش زبانی را کنار هم بسنجد.
نسخه عمومی میتواند از شراکت مسئولانه با صاحبان محتوای فارسی حرف بزند. نسخه خصوصی باید لیست شرکا، شرایط، قیمت، محدودیت انتشار، درآمد سهم، دستهبندی مجوز و حق وتو قوانین را نگه دارد. این بخش برای سرمایهگذار مهم است چون نشان میدهد داده مزیت دفاعی فقط خزنده داده نیست؛ شبکه قرارداد و اعتماد است.
محتوا حقوق، سازنده محتوا رضایت و فارسی پیکره داده بازارگاه
مدل فارسی جدی نمیتواند بر پایه تصور «هر محتوای آنلاین آزاد است» ساخته شود. حق نشر، رضایت خالق، ارزش اقتصادی آرشیو، حساسیت فرهنگی و امکان خروج از برنامه باید از ابتدا در برنامه داده دیده شود. صاحبان کتاب، صوت، مقاله، خبر، محتوای آموزشی، شعر، داستان، زیرنویس، پادکست و اسناد سازمانی باید بدانند داده آنها برای چه استفاده میشود: بازیابی، ارزیابی، معیارسنجی، تنظیم دقیق محدود یا آموزش مدل گسترده. هر سطح استفاده قرارداد و ارزش پیشنهادی جدا میخواهد.
فارسی پیکره داده بازارگاه میتواند راه سالمتری از استخراج وب خام باشد. آپالکسا میتواند برای صاحبان محتوا ابزار بدهد: فهرست خدمات کردن آرشیو، OCR/پاکسازی، جستوجوی هوشمند، خلاصهسازی کنترلشده، گزارش کیفیت، مجموعهداده کارت، نشانگذاری فایل یا انتساب، درآمد سهم و نمای مدیریتی مصرف. در مقابل، صاحب محتوا میتواند اجازه استفاده مشخص بدهد. این مدل هم مزیت دفاعی داده میسازد و هم ریسک حقوقی و اعتباری را کمتر میکند.
نسخه عمومی میتواند اصل رضایت، مجوز و ارزش برگشتی برای خالقان فارسی را منتشر کند. نسخه خصوصی باید شریک خط پردازش، مدل قیمتگذاری، درآمد-سهم شرایط، خروج از برنامه فرایند، مجموعهداده کارتها، حقوقی نظرها، محدودشده پیکرههای داده و برنامه مذاکره با صاحبان محتوا را نگه دارد. این بخش به سرمایهگذار نشان میدهد دیتای فارسی برای آپالکسا دارایی قراردادی و قابل دفاع است، نه فقط فایل جمعآوریشده.
بازیابی پیکره داده، ارجاعها و دانش محلی قابل اعتماد
برای بسیاری از کاربردهای فارسی، پاسخ درست از حافظه مدل نمیآید؛ از بازیابی قابل اعتماد میآید. Aira، ابزارهای سازمانی، پشتیبانی، کشاورزی، فروشگاه و ANI به پیکره دادههای فارسی نیاز دارند که منبع، تاریخ، مجوز، کیفیت و دامنهشان مشخص باشد. اگر مدل به متن نامطمئن وب تکیه کند، پاسخ روان اما غلط میدهد؛ اگر بازیابی با ارجاع منبع و تازگی داده کنترل شود، اعتماد محصولی بیشتر میشود.
بازیابی پیکره داده باید چند نوع داشته باشد: محتوای عمومی و امن، اسناد دارای مجوز، دانش سازمانی محیط مشتری، راهنماهای محصولی، واژهنامه فارسی، داده صنفی، و معیارسنجی خصوصی. هر پیکره داده باید ورود داده، حذف رخداد تکراری، نرمالسازی، بخشبندی، فراداده، دسترسی دامنه، ارجاع منبع قالب، تازگی داده و حذف خطمشی داشته باشد. برای فارسی، ارجاع منبع باید با UI راستبهچپ، تاریخ جلالی/میلادی و نام منبع قابل فهم نمایش داده شود.
نسخه عمومی میتواند بگوید آپالکسا فارسی را با دانش قابل ارجاع و مجاز پشتیبانی میکند. نسخه خصوصی باید پیکره داده فهرست، مجوزدهی شرایط، رتبهبندی، بردار معنایی مدل، بخشبندی خطمشی، منبع کیفیت امتیازها، بازیابی ارزیابی و دادههای محیط مشتری را نگه دارد.
محصولات آپالکسا بهعنوان آزمایشگاه فارسی
مزیت آپالکسا این است که فارسی را فقط در چکیده نمیسنجد. هر محصول یک آزمایشگاه زنده است. Aira زبان عمومی، صوت و حافظه شخصی را نشان میدهد. بارکد زبان کالا، فاکتور و کسبوکار کوچک و متوسط را میدهد. Aira پشتیبانی و فروش مکالمه مشتری و فروش را تولید میکنند. Nahid روایت، داستان و صوت فرهنگی را وارد میکند. Socheli لحن برند و محتوای اجتماعی را میسنجد.
این دادهها نباید بیمرز برای آموزش مدل استفاده شوند؛ اما میتوانند برای تعریف معیارسنجی، خطاهای رایج، نیازهای UX، ارزیابی و طراحی دستور فارسی استفاده شوند. همین اتصال محصول به پژوهش باعث میشود برنامه فارسی از مقاله دانشگاهی فاصله بگیرد و به کیفیت حلقه واقعی تبدیل شود.
نسخه عمومی باید این اکوسیستم را نشان دهد. نسخه خصوصی باید مرز داده هر محصول، رضایت، ناشناسسازی، کاربرد مجاز، ارزیابی بسته و برنامه همکاری پژوهشی را مشخص کند.
انتشار نسخه نظم مهندسی و جدول رتبهبندی داخلی فارسی
برنامه فارسی باید انتشار نسخه نظم مهندسی داشته باشد. هر مدل، دستور بسته، گفتار مدل یا بازیابی خطمشی قبل از استفاده محصولی باید روی مجموعهای از معیارسنجیهای فارسی اجرا شود. نتیجه باید فقط یک امتیاز کلی نباشد؛ باید نشان دهد مدل در لحن رسمی، پشتیبانی عصبانی، نیمفاصله، تاریخ جلالی، محتوای کودک، سند مالی، صوت نویزی و ایمنی چه وضعی دارد.
جدول رتبهبندی داخلی به تیم محصول کمک میکند تصمیم بگیرد کدام مدل برای کدام کار مناسب است. شاید یک مدل برای مکالمه عمومی خوب باشد اما برای OCR/فاکتور ضعیف. شاید یک مدل کوچک برای طبقهبندی پشتیبانی کافی باشد و هزینه را کم کند. این انتخابها باید با داده انجام شوند، نه با حس لحظهای از چند دستور.
در نسخه عمومی میتوان گفت آپالکسا کیفیت فارسی را با معیارسنجیهای محصولی میسنجد. نسخه خصوصی باید امتیاز مدلها، خطاهای واقعی، آستانه انتشار نسخه، هزینه استنتاج، و تصمیمهای مدل مسیریابی را نگه دارد.
انتشار نسخه دروازهها برای هر سطح محصول فارسی
همه قابلیتهای فارسی نباید با یک دروازه تصمیم منتشر شوند. پاسخ عمومی Aira، پشتیبانی مشتری، مکاتبه رسمی، محتوای کودک، تحلیل سند، تماس صوتی و ابزار مالی ریسک یکسان ندارند. بنابراین برنامه فارسی باید دروازه کنترل انتشار نسخه سطحبندیشده داشته باشد: آزمایشی داخلی، شریک بتا، عمومی کمخطر، بهرهبرداری واقعی دستیار، و بهرهبرداری واقعی اقدام. هر سطح معیار کیفیت، ایمنی، انسانی بازبینی و بازگشت خودش را میخواهد.
برای مثال، یک صدا مدل که در مکالمه عمومی خوب است شاید هنوز برای تماس پشتیبانی آماده نباشد. یک دستور بسته که نامه رسمی خوب مینویسد شاید برای پاسخ حقوقی یا مالی نباید فعال شود. اگر انتشار نسخه نظم مهندسی در محصول سطح تعاملها اجرا نشود، معیارسنجی داخلی ارزش عملی خود را از دست میدهد. هر محصول باید بداند با کدام مدل، کدام نسخه، کدام آستانه و کدام مسیر جایگزین کار میکند.
نسخه عمومی میتواند از انتشار مسئولانه و مرحلهای کیفیت فارسی حرف بزند. نسخه خصوصی باید دروازه تصمیم ماتریس، محصول آستانهها، بازگشت برنامه، مدل مسیریابی، رخداد معیارها، مالکهای انتشار نسخه و شناختهشده شکست مجموعهها را نگه دارد.
آزمایشگاه تجربه کاربری فارسی و تست انسانی محصولی
کیفیت فارسی فقط با معیارسنجی ماشینی ثابت نمیشود. باید آزمایشگاه تجربه کاربری فارسی وجود داشته باشد: کاربران واقعی، نقشهای مختلف، سناریوهای پشتیبانی، فروش، داستان، کودک، سازمان، صوت و موبایل با محصول کار کنند و خطاها ثبت شود. مدل ممکن است در معیارسنجی خوب باشد اما در UI، پیام خطا، زمان پاسخ، حافظه رفتار یا لحن چندنوبتی تجربه بد بسازد.
این آزمایشگاه باید ساختاریافته باشد. هر تست باید پرسونا، وظیفه، زمینه، انتظار، خروجی، خطای زبانی، خطای فرهنگی، خطای UI، سطح ناراحتی کاربر و پیشنهاد اصلاح داشته باشد. بعضی تستها عمومی و پژوهشیاند؛ بعضی به محصولات و داده مشتری وصلاند و باید محرمانه بمانند. خروجی آزمایشگاه باید به سبک راهنما، معیارسنجی، دستور، UI متن رابط و آموزش مدل داده برگردد.
از نظر سرمایهگذاری، آزمایشگاه تجربه کاربری نشان میدهد آپالکسا فارسی را فقط پژوهش نمیبیند؛ آن را به دوره نگهداری و پذیرش محصولی وصل میکند. نسخه عمومی میتواند از تست انسانی فارسی و تجربه بومی حرف بزند. نسخه خصوصی باید پروتکل تست، شرکتکنندگان، ویدئوها، خطاها، هزینه پژوهش و نقشه راه اصلاحات را نگه دارد.
گویش/ثبت ماتریس پوشش و ارزیابی گروههای کاربری
فارسی یکدست نیست. مدل باید فارسی رسمی، محاورهای، اداری، صنفی، کودک، دانشگاهی، رسانهای، شعر/داستان، فینگلیش، کد-تغییر زبان و لهجههای گفتاری را به شکل متفاوت بسنجد. پوشش ماتریس باید نشان دهد هر محصول آپالکسا به کدام ثبت نیاز دارد و هر مدل در همان ثبت چه کیفیتی دارد. Aira مصرفی، Nahid، پشتیبانی، فروش و ابزار سازمانی نیاز یکسان ندارند.
ارزیابی گروه کاربریها باید از کاربر و کاربرد واقعی ساخته شوند. مثلاً پشتیبانی مشتری باید پیام عصبانی، مودب، مبهم، فینگلیش و چندنوبتی داشته باشد. Nahid باید روایت ادبی، کودک و صوت راوی را بسنجد. فروش باید لحن فروش و اعتراض مشتری فارسی را ببیند. ابزار اداری باید تاریخ، نامه رسمی، فرم و اصطلاحات سازمانی را درست بفهمد. اگر معیارسنجی فقط متن تمیز وب باشد، محصولهای واقعی را نمایندگی نمیکند.
نسخه عمومی میتواند بگوید آپالکسا کیفیت فارسی را برای ثبتها و کاربردهای مختلف میسنجد. نسخه خصوصی باید ماتریس پوشش، گروه کاربری تعریفها، جمعیتشناختی/حریم خصوصی محدودیتها، نمونهگیری برنامه، ارزیابی امتیازها، شکست مجموعهها و برنامه جبران شکاف داده را نگه دارد. این بخش برای جلوگیری از ادعای کلی «مدل فارسی خوب» ضروری است.
ارزیابی صوت، لهجه و مکالمه چندنوبتی
صوت فارسی فقط STT نیست. تجربه صوتی واقعی شامل تشخیص گفتار، فهم نیت، مدیریت مکالمه چندنوبتی، پاسخ کوتاه و طبیعی، اصلاح خطا، تشخیص سکوت، و بازگشت به زمینه قبلی است. لهجه، نویز، سرعت، نامهای خاص، فینگلیش و کد-تغییر زبان باید در ارزیابی دیده شوند. اگر فقط متن رونوشت را بسنجیم، کیفیت تجربه صوتی پنهان میماند.
برنامه ارزیابی صوت باید چند مجموعه داشته باشد: صوت تمیز، تماس تلفنی نویزی، گفتار محاورهای، مکالمه کاری، نامهای محلی، واژههای انگلیسی داخل جمله، جملههای نیمهتمام و سناریوهای حساس. خروجی باید شاخصهای متفاوت بدهد: واژه خطا، نیت دقت، اصلاح موفقیت، تاخیر، کاربر مزاحمت/قطع جریان، و ایمنی. برای Aira مصرفی، تماسها و پشتیبانی، اینها مستقیماً روی دوره نگهداری و اعتماد اثر دارند.
نسخه عمومی میتواند بگوید فارسی صوتی بخشی از هویت محصول است. نسخه خصوصی باید فایلهای صوتی، رضایت، لهجهها، معیارسنجیها، خطاهای مدل، ارائهدهنده ترکیب، هزینه دقیقه و برنامه بهبود گفتار را نگه دارد.
فارسی زمینگیرسازی محلی کتابخانه: تقویم، نامها، مکانها و واحدها
بخشی از ضعف فارسی از نداشتن زمینگیرسازی محلی کتابخانه محلی میآید. مدل باید تاریخ جلالی و میلادی، نامهای ایرانی، شهرها و استانها، واحد پول، واحدهای اندازهگیری، اصطلاحات صنفی، اعداد فارسی/عربی/لاتین، کدپستی، شماره تلفن، نام سازمانها و ترکیب فارسی/انگلیسی را درست بفهمد. اینها فقط مسئله توکنساز نیستند؛ بخشی از دانش عملیاتی محصولاند.
زمینگیرسازی محلی کتابخانه باید برای محصولهای مختلف قابل استفاده باشد: بارکد برای کالا و قیمت، Aira برای زندگی روزمره، فروش برای شرکتها، پشتیبانی برای شماره سفارش و زمان، کشاورزی برای واحد زمین و آب، و ANI برای خدمات عمومی. این کتابخانه میتواند شامل نرمالسازی، موجودیت حلکننده، بافت زبانی/محلی قوانین، اعتبارسنجی و موارد آزمون باشد. وقتی مدل عدد یا تاریخ را اشتباه میفهمد، خطا گاهی مالی یا عملیاتی میشود.
نسخه عمومی میتواند بگوید آپالکسا فارسی را با کتابخانههای محلی برای تاریخ، نام، واحد و دانش زمینهای محصول پشتیبانی میکند. نسخه خصوصی باید موجودیت فهرستها، نرمالسازی قوانین، حلکننده طراحی، محصول-اختصاصی نگاشتها، ارزیابی موارد و خطاهای واقعی را نگه دارد. این بخش تز را به زیرساخت قابل استفاده در محصولات وصل میکند.
توکنساز، نرمالسازی و خطای ظریف فارسی
کیفیت فارسی از سطح کاراکتر شروع میشود. ی و ک عربی/فارسی، نیمفاصله، اعداد فارسی و لاتین، علائم، فاصلههای اضافی، فینگلیش و OCR خراب میتوانند هم آموزش مدل را آلوده کنند و هم ارزیابی را گمراه کنند. اگر خط پردازش نرمالسازی دقیق نباشد، مدل خطاهایی یاد میگیرد که در تجربه کاربر به شکل بیدقتی دیده میشود.
توکنساز و پیشپردازش باید با متن فارسی واقعی سنجیده شود، نه فقط پیکره داده تمیز. باید ببینیم کلمات مرکب، پسوندها، نامها، اصطلاحات صنفی، تاریخ جلالی، واحد پول، شماره تلفن، آدرس و متن محاورهای چگونه قطعهبندی میشوند. در بعضی کاربردها، حفظ شکل اصلی متن مهم است؛ در بعضی دیگر، نرمالسازی برای بازیابی بهتر است. یک خطمشی واحد برای همه کارها کافی نیست.
نسخه عمومی میتواند نشان دهد آپالکسا فارسی را در جزئیات فنی جدی میگیرد. نسخه خصوصی باید نرمالسازی قوانین، توکنساز ارزیابی، خطا مجموعهها، OCR پاکسازی و تصمیمهای پیشپردازش را نگه دارد.
انتشار عمومی خطمشی، تکرارپذیری بسته و ایمن باز/متنباز معیارسنجی حاکمیت
انتشار معیارسنجی فارسی میتواند اعتبار علمی بسازد، اما اگر بیدقت باشد، هم داده حساس را افشا میکند و هم به مدلها یاد میدهد آزمون را حفظ کنند. انتشار عمومی خطمشی باید مشخص کند چه چیزی باز/متنباز میشود، چه چیزی فقط under مجوز است، چه چیزی فقط در جدول رتبهبندی داخلی میماند، و چه چیزی به دلیل حریم خصوصی یا آلودگی داده خطر منتشر نمیشود.
تکرارپذیری بسته باید بدون افشای داده ممنوع، روش را قابل بررسی کند: وظیفه تعریف، برچسبگذاری معیار داوری، امتیازدهی، نمونههای مجاز، داده بیانیه، مدل کارت، شناختهشده محدودیتها و آلودگی داده بررسیها. ایمن معیارسنجی حاکمیت باید نسخهبندی، حذف حقوقی، اصلاحیهها، بازبین دسترسی و تعارض-مورد توجه را هم داشته باشد. این برای همکاری دانشگاهی و سرمایهگذار هر دو مهم است.
نسخه عمومی میتواند از معیارسنجیهای امن، قابل بازتولید و مسئولانه برای فارسی حرف بزند. نسخه خصوصی باید منتشرنشده آزمون مجموعهها، مجوزدهی شرایط، بازبین فهرست، آلودگی داده تحلیل، حذف حقوقی فرایند و شریک توافقها را نگه دارد. این بخش تز فارسی را به اعتبار بیرونی بدون از دست دادن مزیت دفاعی داده وصل میکند.
همکاری پژوهشی و انتشار معیارسنجیهای امن
برای اعتبار عمومی، برنامه فارسی باید فقط ادعای داخلی نباشد. آپالکسا میتواند بخشی از معیارسنجیها، روش ارزیابی، خطاهای عمومی و مقالههای فنی را به شکل امن منتشر کند. این کار به جذب پژوهشگر، شریک دانشگاهی، ناشر و سرمایهگذار کمک میکند، بدون اینکه مجموعهدادههای حساس یا مزیت تجاری خام را لو بدهد.
انتشار معیارسنجی باید دو نسخه داشته باشد: نسخه عمومی کوچک و امن برای مقایسه عمومی، و نسخه خصوصی بزرگتر برای تصمیم محصولی. عمومی بسته نباید شامل داده مشتری، قرارداد محتوا یا نمونه قابل شناسایی باشد. خصوصی بسته باید برای انتشار نسخه واقعی سختگیرتر و نزدیکتر به کاربردهای آپالکسا باشد.
نسخه عمومی این تز میتواند دعوت به همکاری پژوهشی کند. نسخه خصوصی باید شریکهای پژوهشی، مالکیت فکری خطمشی، هزینه برچسبگذاری، معیار انتشار، و خط قرمزهای داده را نگه دارد.
سرمایهگذار روایت: مزیت دفاعی داده، کیفیت فارسی و پلتفرمسازی محصولات
برای سرمایهگذار، تز فارسی فقط مسئله فرهنگی نیست؛ مسئله مزیت دفاعی و بازار است. اگر آپالکسا بتواند داده مجاز، معیارسنجی معتبر، سبک راهنما، زمینگیرسازی محلی کتابخانه، گفتار پیکره داده، آزمایشگاه تجربه کاربری و حلقه محصولی بین Aira، بارکد، پشتیبانی، فروش، Nahid و ANI بسازد، کیفیت فارسی به دارایی پلتفرمی تبدیل میشود. این دارایی در هر محصول هزینه جذب، دوره نگهداری و اعتماد را بهتر میکند.
سرمایهگذار روایت باید نشان دهد این کار چرا قابل دفاع است. مدل عمومی جهانی میتواند فارسی تولید کند، اما داده محلی، قرارداد محتوا، ارزیابی واقعی، لحن محصولی، اتصالدهندههای بازار ایران و بازخورد از محصولات زنده به راحتی کپی نمیشود. این مزیت دفاعی بهخصوص وقتی مهم میشود که مشتری سازمانی، دیتاسنتر محلی، ANI و ابزار داخلی به کیفیت فارسی قابل ممیزی نیاز دارند.
نسخه عمومی میتواند ارزش بازار و هویت محصولی فارسی را توضیح دهد. نسخه خصوصی باید اندازه بازار، هزینه توسعه زیرساخت، مجموعهداده ارزشگذاری، خط زمانی کیفیت، ریسک رقبا، شریک خط پردازش و اثر روی درآمد محصولات را نگه دارد. این بخش پایان تز را از بیانیه نظری به یادداشت سرمایهپذیر تبدیل میکند.
چرا این تز برای بازار و سرمایهگذار مهم است
اگر آپالکسا بتواند نشان دهد که فارسی را بهعنوان هسته محصول میبیند، نه لایه ترجمه، از بسیاری از رقبا جدا میشود. بازار فارسی بزرگ است، اما کاربران وقتی ابزارها واقعاً با زبان و کارشان هماهنگ نباشند، سریع اعتمادشان را از دست میدهند. کیفیت فارسی میتواند دوره نگهداری، واژه of دهان/گفتار و پذیرش سازمانی را بالا ببرد.
این تز همچنین به برنامههای بزرگتر وصل است: ANI برای ایران، مدل بنیادین فارسی، دیتاسنتر محلی، Aira مصرفی، Nahid فرهنگی و ابزارهای سازمانی. همه اینها به داده و هویت فارسی نیاز دارند. بنابراین مقاله عمومی باید این پیوند را روشن کند و نشان دهد چرا آپالکسا روی فارسی سرمایهگذاری میکند.
نسخه خصوصی باید سختتر و عددیتر باشد: هزینه داده، قرارداد محتوا، معیارسنجی، تیم زبان، توان محاسباتی، مدلهای پایه، ارزیابی خطر، و مسیر انتشار پژوهشی. عمومیکردن همه جزئیات مجموعهداده اشتباه است؛ اما عمومیکردن تز اعتماد و اعتبار میسازد.
گالری تصویر تولیدی
برای هر سند، تصاویر تولیدی و دستورهای تصویرسازی کنار هم نگه داشته میشوند تا نسخه عمومی و نسخه سرمایهگذار قابل گسترش باشند.
فارسی در هسته
تصویر فرایند: نمای «فارسی در هسته» برای توضیح مسیر اجرای «هوش مصنوعی فارسی ترجمه نیست». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیتجربه بومی
تصویر فرایند: نمای «تجربه بومی» برای توضیح مسیر اجرای «هوش مصنوعی فارسی ترجمه نیست». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیبنچمارک فارسی
تصویر فرایند: نمای «بنچمارک فارسی» برای توضیح مسیر اجرای «هوش مصنوعی فارسی ترجمه نیست». معماری، جریان داده و نقاط تصمیم عملیاتی را ملموستر میکند.
مناسب انتشار عمومیمحصولات مرتبط و منابع
منابع پایین، نقطه شروع تحقیق عمیقترند؛ برای نسخه نهایی هر مقاله باید منابع بیشتری اضافه شود.